instable checkpointing after migration to flink 1.8

instable checkpointing after migration to flink 1.8

|
Hi all,
We have a flink job with user state, checkpointing to RocksDBBackend which is externally stored in AWS S3. After we have migrated our cluster from 1.6 to 1.8, we see occasionally that some slots do to acknowledge the checkpoints quick enough. As an example: All slots acknowledge between 30-50 seconds except only one slot acknowledges in 15 mins. Checkpoint sizes are similar to each other, like 200-400 MB. We did not experience this weird behaviour in Flink 1.6. We have 5 min checkpoint interval and this happens sometimes once in an hour sometimes more but not in all the checkpoint requests. Please see the screenshot below. Also another point: For the faulty slots, the duration is consistently 15 mins and some seconds, we couldn’t find out where this 15 mins response time comes from. And each time it is a different task manager, not always the same one. Do you guys aware of any other users having similar issues with the new version and also a suggested bug fix or solution? 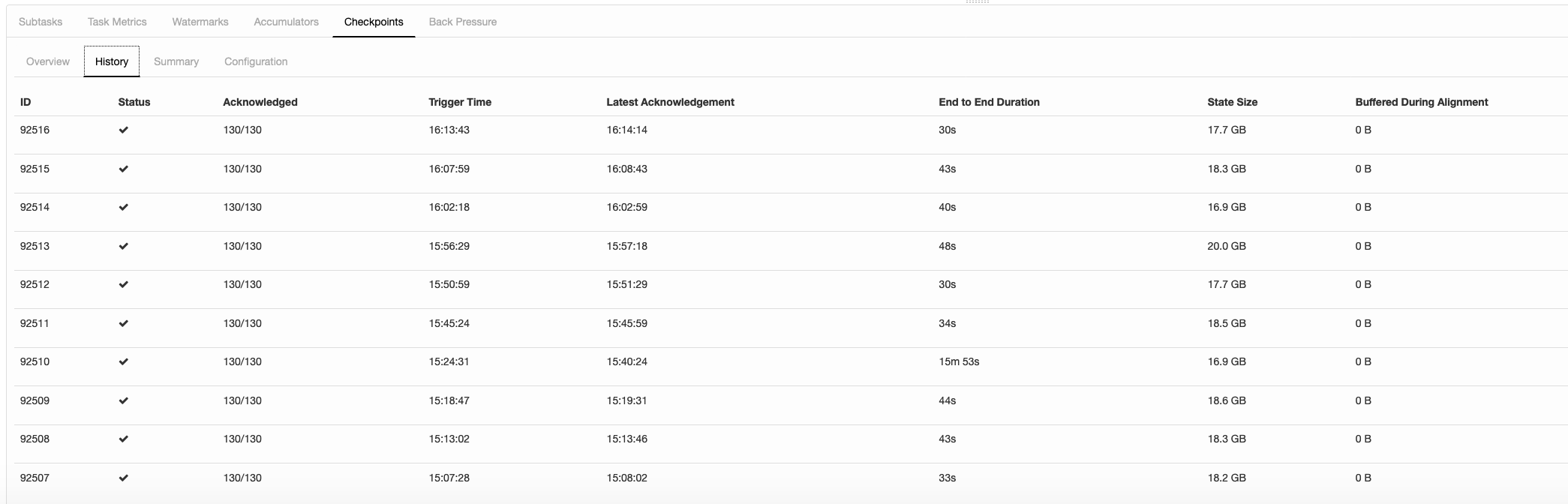  Thanks in advance, Bekir Oguz
|
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Bekir First of all, I think there is something wrong. the state size is almost the same, but the duration is different so much. The checkpoint for RocksDBStatebackend is dump sst files, then copy the needed sst files(if you enable incremental checkpoint, the sst files already on remote will not upload), then complete checkpoint. Can you check the network bandwidth usage during checkpoint? Best, Congxian Bekir Oguz <[hidden email]> 于2019年7月16日周二 下午10:45写道:
|
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Bekir,
Another user reported checkpointing issues with Flink 1.8.0 [1]. These seem to be resolved with Flink 1.8.1. Hope this helps, Fabian [1] https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < [hidden email]>: > Hi Bekir > > First of all, I think there is something wrong. the state size is almost > the same, but the duration is different so much. > > The checkpoint for RocksDBStatebackend is dump sst files, then copy the > needed sst files(if you enable incremental checkpoint, the sst files > already on remote will not upload), then complete checkpoint. Can you check > the network bandwidth usage during checkpoint? > > Best, > Congxian > > > Bekir Oguz <[hidden email]> 于2019年7月16日周二 下午10:45写道: > >> Hi all, >> We have a flink job with user state, checkpointing to RocksDBBackend >> which is externally stored in AWS S3. >> After we have migrated our cluster from 1.6 to 1.8, we see occasionally >> that some slots do to acknowledge the checkpoints quick enough. As an >> example: All slots acknowledge between 30-50 seconds except only one slot >> acknowledges in 15 mins. Checkpoint sizes are similar to each other, like >> 200-400 MB. >> >> We did not experience this weird behaviour in Flink 1.6. We have 5 min >> checkpoint interval and this happens sometimes once in an hour sometimes >> more but not in all the checkpoint requests. Please see the screenshot >> below. >> >> Also another point: For the faulty slots, the duration is consistently 15 >> mins and some seconds, we couldn’t find out where this 15 mins response >> time comes from. And each time it is a different task manager, not always >> the same one. >> >> Do you guys aware of any other users having similar issues with the new >> version and also a suggested bug fix or solution? >> >> >> >> >> Thanks in advance, >> Bekir Oguz >> > |
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Fabian,
Thanks for sharing this with us, but we’re already on version 1.8.1. What I don’t understand is which mechanism in Flink adds 15 minutes to the checkpoint duration occasionally. Can you maybe give us some hints on where to look at? Is there a default timeout of 15 minutes defined somewhere in Flink? I couldn’t find one. In our pipeline, most of the checkpoints complete in less than a minute and some of them completed in 15 minutes+(less than a minute). There’s definitely something which adds 15 minutes. This is happening in one or more subtasks during checkpointing. Please see the screenshot below: 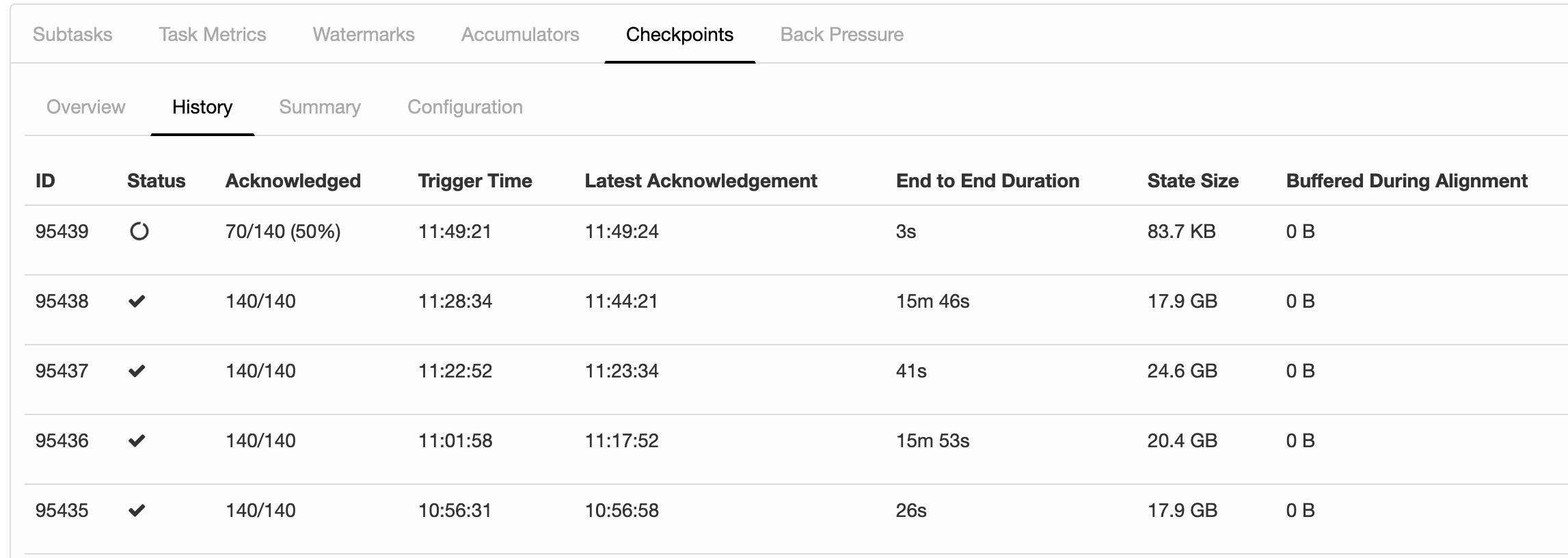 Regards, Bekir
|
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Bekir I'll first comb through all the information here, and try to find out the reason with you, maybe need you to share some more information :) Best, Congxian Bekir Oguz <[hidden email]> 于2019年8月1日周四 下午5:00写道:
|
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Bekir I’ll first summary the problem here(please correct me if I’m wrong) 1. The same program runs on 1.6 never encounter such problems 2. Some checkpoints completed too long (15+ min), but other normal checkpoints complete less than 1 min 3. Some bad checkpoint will have a large sync time, async time seems ok 4. Some bad checkpoint, the e2e duration will much bigger than (sync_time + async_time) First, answer the last question, the e2e duration is ack_time - trigger_time, so it always bigger than (sync_time + async_time), but we have a big gap here, this may be problematic. According to all the information, maybe the problem is some task start to do checkpoint too late and the sync checkpoint part took some time too long, Could you please share some more information such below: - A Screenshot of summary for one bad checkpoint(we call it A here) - The detailed information of checkpoint A(includes all the problematic subtasks) - Jobmanager.log and the taskmanager.log for the problematic task and a health task - Share the screenshot of subtasks for the problematic task(includes the `Bytes received`, `Records received`, `Bytes sent`, `Records sent` column), here wants to compare the problematic parallelism and good parallelism’s information, please also share the information is there has a data skew among the parallelisms, - could you please share some jstacks of the problematic parallelism — here wants to check whether the task is too busy to handle the barrier. (flame graph or other things is always welcome here) Best, Congxian Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道:
|
Re: instable checkpointing after migration to flink 1.8
|
|
cc Bekir Best, Congxian Congxian Qiu <[hidden email]> 于2019年8月2日周五 下午12:23写道:
|
Re: instable checkpointing after migration to flink 1.8
|
|
In reply to this post by Congxian Qiu
Hi Congxian,
I was able to fetch the logs of the task manager (attached) and the screenshots of the latest long checkpoint. I will get the logs of the job manager for the next long running checkpoint. And also I will try to get a jstack during the long running checkpoint. Note: Since at the Subtasks tab we do not have the subtask numbers, and at the Details tab of the checkpoint, we have the subtask numbers but not the task manager hosts, it is difficult to match those. We’re assuming they have the same order, so seeing that 3rd subtask is failing, I am getting the 3rd line at the Subtasks tab which leads to the task manager host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a great feature if you guys also include the subtask-id’s to the Subtasks view.*** Note: timestamps in the task manager log are in UTC and I am at the moment at zone UTC+3, so the time 10:30 at the screenshot matches the time 7:30 in the log. Kind regards, Bekir
|
Re: instable checkpointing after migration to flink 1.8
|
|
Forgot to add the checkpoint details after it was complete. This is for that long running checkpoint with id 95632.
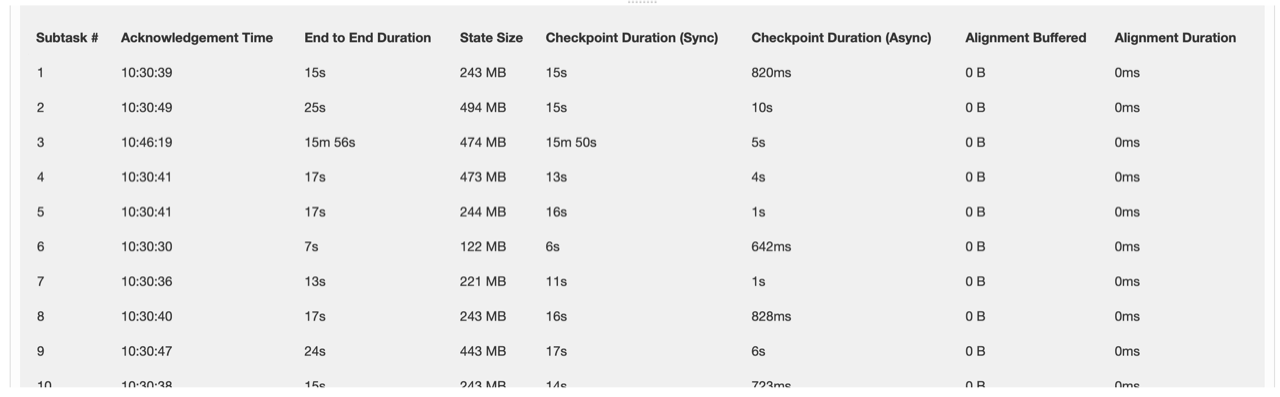
|
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Bekir Cloud you please also share the below information: - jobmanager.log - taskmanager.log(with debug info enabled) for the problematic subtask. - the DAG of your program (if can provide the skeleton program is better -- can send to me privately) For the subIndex, maybe we can use the deploy log message in jobmanager log to identify which subtask we want. For example in JM log, we'll have something like "2019-08-02 11:38:47,291 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Deploying Source: Custom Source (2/2) (attempt #0) to container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee (dataPort=39488)" then we know "Custum Source (2/2)" was deplyed to "aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still more than one subtasks in one contain :( Best, Congxian Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道:
|
Re: instable checkpointing after migration to flink 1.8
|
|
CC flink dev mail list
Update for those who may be interested in this issue, we'are still diagnosing this problem currently. Best, Congxian Congxian Qiu <[hidden email]> 于2019年8月29日周四 下午8:58写道: > Hi Bekir > > Currently, from what we have diagnosed, there is some task complete its > checkpoint too late (maybe 15 mins), but we checked the kafka broker log > and did not find any interesting things there. could we run another job, > that did not commit offset to kafka, this wants to check if it is the > "commit offset to kafka" step consumes too much time. > > Best, > Congxian > > > Bekir Oguz <[hidden email]> 于2019年8月28日周三 下午4:19写道: > >> Hi Congxian, >> sorry for the late reply, but no progress on this issue yet. I checked >> also the kafka broker logs, found nothing interesting there. >> And we still have 15 min duration checkpoints quite often. Any more ideas >> on where to look at? >> >> Regards, >> Bekir >> >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email]> >> wrote: >> >>> Hi Bekir >>> >>> Do you come back to work now, does there any more findings of this >>> problem? >>> >>> Best, >>> Congxian >>> >>> >>> Bekir Oguz <[hidden email]> 于2019年8月13日周二 下午4:39写道: >>> >>>> Hi Congxian, >>>> Thanks for following up this issue. It is still unresolved and I am on >>>> vacation at the moment. Hopefully my collegues Niels and Vlad can spare >>>> some time to look into this. >>>> >>>> @Niels, @Vlad: do you guys also think that this issue might be Kafka >>>> related? We could also check kafka broker logs at the time of long >>>> checkpointing. >>>> >>>> Thanks, >>>> Bekir >>>> >>>> Verstuurd vanaf mijn iPhone >>>> >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu <[hidden email]> >>>> het volgende geschreven: >>>> >>>> Hi Bekir >>>> >>>> Is there any progress about this problem? >>>> >>>> Best, >>>> Congxian >>>> >>>> >>>> Congxian Qiu <[hidden email]> 于2019年8月8日周四 下午11:17写道: >>>> >>>>> hi Bekir >>>>> Thanks for the information. >>>>> >>>>> - Source's checkpoint was triggered by RPC calls, so it has the >>>>> "Trigger checkpoint xxx" log, >>>>> - other task's checkpoint was triggered after received all the barrier >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( >>>>> >>>>> Your diagnose makes sense to me, we need to check the Kafka log. >>>>> I also find out that we always have a log like >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator Marking >>>>> the coordinator 172.19.200.73:9092 (id: 2147483646 rack: null) dead >>>>> for group userprofileaggregator >>>>> 2019-08-06 13:58:49,872 DEBUG >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - Notifica", >>>>> >>>>> I checked the doc of kafka[1], only find that the default of ` >>>>> transaction.max.timeout.ms` is 15 min >>>>> >>>>> Please let me know there you have any finds. thanks >>>>> >>>>> PS: maybe you can also checkpoint the log for task >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message late also. >>>>> >>>>> [1] https://kafka.apache.org/documentation/ >>>>> Best, >>>>> Congxian >>>>> >>>>> >>>>> Bekir Oguz <[hidden email]> 于2019年8月7日周三 下午6:48写道: >>>>> >>>>>> Hi Congxian, >>>>>> Thanks for checking the logs. What I see from the logs is: >>>>>> >>>>>> - For the tasks like "Source: >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” {17, 27, 31, >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also ‘Confirm >>>>>> checkpoint’ log lines, with 15 mins delay in between. >>>>>> - For the tasks like “KeyedProcess -> (Sink: >>>>>> profileservice-userprofiles_kafka_sink, Sink: >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We DO NOT have >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm checkpoint’ lines. >>>>>> >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator logs >>>>>> about lost connection to Kafka at the same time we have the checkpoints >>>>>> confirmed. This 15 minutes delay might be because of some timeout at the >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka coordinator >>>>>> dead, and then discovering kafka coordinator again. >>>>>> >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot confirm >>>>>> the checkpoints, cannot send the async offset commit request to Kafka. This >>>>>> could be the root cause of the problem. Please see the attached logs >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a 15 minutes >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 and 9:52) >>>>>> >>>>>> >>>>>> I will enable Kafka DEBUG logging to see more and let you know about >>>>>> the findings. >>>>>> >>>>>> Thanks a lot for your support, >>>>>> Bekir Oguz >>>>>> >>>>>> >>>>>> >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu <[hidden email]> >>>>>> het volgende geschreven: >>>>>> >>>>>> Hi >>>>>> >>>>>> Received all the files, as a first glance, the program uses at least >>>>>> once checkpoint mode, from the tm log, maybe we need to check checkpoint of >>>>>> this operator "Invoking async call Checkpoint Confirmation for KeyedProcess >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task KeyedProcess -> >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", >>>>>> >>>>>> Seems it took too long to complete the checkpoint (maybe something >>>>>> about itself, or maybe something of Kafka). I'll go through the logs >>>>>> carefully today or tomorrow again. >>>>>> >>>>>> Best, >>>>>> Congxian >>>>>> >>>>>> >>>>>> Bekir Oguz <[hidden email]> 于2019年8月6日周二 下午10:38写道: >>>>>> >>>>>>> Ok, I am removing apache dev group from CC. >>>>>>> Only sending to you and my colleagues. >>>>>>> >>>>>>> >>>>>>> Thanks, >>>>>>> Bekir >>>>>>> >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz <[hidden email]> >>>>>>> het volgende geschreven: >>>>>>> >>>>>>> Hi Congxian, >>>>>>> Previous email didn’t work out due to size limits. >>>>>>> I am sending you only job manager log zipped, and will send other >>>>>>> info in separate email. >>>>>>> <jobmanager_sb77v.log.zip> >>>>>>> Regards, >>>>>>> Bekir >>>>>>> >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu <[hidden email]> >>>>>>> het volgende geschreven: >>>>>>> >>>>>>> Hi Bekir >>>>>>> >>>>>>> Cloud you please also share the below information: >>>>>>> - jobmanager.log >>>>>>> - taskmanager.log(with debug info enabled) for the problematic >>>>>>> subtask. >>>>>>> - the DAG of your program (if can provide the skeleton program is >>>>>>> better -- can send to me privately) >>>>>>> >>>>>>> For the subIndex, maybe we can use the deploy log message in >>>>>>> jobmanager log to identify which subtask we want. For example in JM log, >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - Deploying Source: >>>>>>> Custom Source (2/2) (attempt #0) to >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was deplyed to " >>>>>>> aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still more than >>>>>>> one subtasks in one contain :( >>>>>>> >>>>>>> Best, >>>>>>> Congxian >>>>>>> >>>>>>> >>>>>>> Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道: >>>>>>> >>>>>>>> Forgot to add the checkpoint details after it was complete. This is >>>>>>>> for that long running checkpoint with id 95632. >>>>>>>> >>>>>>>> <PastedGraphic-5.png> >>>>>>>> >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz <[hidden email]> >>>>>>>> het volgende geschreven: >>>>>>>> >>>>>>>> Hi Congxian, >>>>>>>> I was able to fetch the logs of the task manager (attached) and the >>>>>>>> screenshots of the latest long checkpoint. I will get the logs of the job >>>>>>>> manager for the next long running checkpoint. And also I will try to get a >>>>>>>> jstack during the long running checkpoint. >>>>>>>> >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask numbers, >>>>>>>> and at the Details tab of the checkpoint, we have the subtask numbers but >>>>>>>> not the task manager hosts, it is difficult to match those. We’re assuming >>>>>>>> they have the same order, so seeing that 3rd subtask is failing, I am >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the task manager >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a great feature if >>>>>>>> you guys also include the subtask-id’s to the Subtasks view.*** >>>>>>>> >>>>>>>> Note: timestamps in the task manager log are in UTC and I am at the >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot matches the time >>>>>>>> 7:30 in the log. >>>>>>>> >>>>>>>> >>>>>>>> Kind regards, >>>>>>>> Bekir >>>>>>>> >>>>>>>> <task_manager.log> >>>>>>>> >>>>>>>> <PastedGraphic-4.png> >>>>>>>> <PastedGraphic-3.png> >>>>>>>> <PastedGraphic-2.png> >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu <[hidden email]> >>>>>>>> het volgende geschreven: >>>>>>>> >>>>>>>> Hi Bekir >>>>>>>> I’ll first summary the problem here(please correct me if I’m wrong) >>>>>>>> 1. The same program runs on 1.6 never encounter such problems >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other normal >>>>>>>> checkpoints complete less than 1 min >>>>>>>> 3. Some bad checkpoint will have a large sync time, async time >>>>>>>> seems ok >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger than >>>>>>>> (sync_time + async_time) >>>>>>>> First, answer the last question, the e2e duration is ack_time - >>>>>>>> trigger_time, so it always bigger than (sync_time + async_time), but we >>>>>>>> have a big gap here, this may be problematic. >>>>>>>> According to all the information, maybe the problem is some task >>>>>>>> start to do checkpoint too late and the sync checkpoint part took some time >>>>>>>> too long, Could you please share some more information such below: >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A here) >>>>>>>> - The detailed information of checkpoint A(includes all the >>>>>>>> problematic subtasks) >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic task >>>>>>>> and a health task >>>>>>>> - Share the screenshot of subtasks for the problematic >>>>>>>> task(includes the `Bytes received`, `Records received`, `Bytes sent`, >>>>>>>> `Records sent` column), here wants to compare the problematic parallelism >>>>>>>> and good parallelism’s information, please also share the information is >>>>>>>> there has a data skew among the parallelisms, >>>>>>>> - could you please share some jstacks of the problematic >>>>>>>> parallelism — here wants to check whether the task is too busy to handle >>>>>>>> the barrier. (flame graph or other things is always welcome here) >>>>>>>> >>>>>>>> Best, >>>>>>>> Congxian >>>>>>>> >>>>>>>> >>>>>>>> Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道: >>>>>>>> >>>>>>>>> Hi Bekir >>>>>>>>> >>>>>>>>> I'll first comb through all the information here, and try to find >>>>>>>>> out the reason with you, maybe need you to share some more information :) >>>>>>>>> >>>>>>>>> Best, >>>>>>>>> Congxian >>>>>>>>> >>>>>>>>> >>>>>>>>> Bekir Oguz <[hidden email]> 于2019年8月1日周四 下午5:00写道: >>>>>>>>> >>>>>>>>>> Hi Fabian, >>>>>>>>>> Thanks for sharing this with us, but we’re already on version >>>>>>>>>> 1.8.1. >>>>>>>>>> >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you maybe give us some >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 minutes defined >>>>>>>>>> somewhere in Flink? I couldn’t find one. >>>>>>>>>> >>>>>>>>>> In our pipeline, most of the checkpoints complete in less than a >>>>>>>>>> minute and some of them completed in 15 minutes+(less than a minute). >>>>>>>>>> There’s definitely something which adds 15 minutes. This is >>>>>>>>>> happening in one or more subtasks during checkpointing. >>>>>>>>>> >>>>>>>>>> Please see the screenshot below: >>>>>>>>>> >>>>>>>>>> Regards, >>>>>>>>>> Bekir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske <[hidden email]> >>>>>>>>>> het volgende geschreven: >>>>>>>>>> >>>>>>>>>> Hi Bekir, >>>>>>>>>> >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 [1]. >>>>>>>>>> These seem to be resolved with Flink 1.8.1. >>>>>>>>>> >>>>>>>>>> Hope this helps, >>>>>>>>>> Fabian >>>>>>>>>> >>>>>>>>>> [1] >>>>>>>>>> >>>>>>>>>> https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E >>>>>>>>>> >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < >>>>>>>>>> [hidden email]>: >>>>>>>>>> >>>>>>>>>> Hi Bekir >>>>>>>>>> >>>>>>>>>> First of all, I think there is something wrong. the state size >>>>>>>>>> is almost >>>>>>>>>> the same, but the duration is different so much. >>>>>>>>>> >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, then >>>>>>>>>> copy the >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the sst >>>>>>>>>> files >>>>>>>>>> already on remote will not upload), then complete checkpoint. Can >>>>>>>>>> you check >>>>>>>>>> the network bandwidth usage during checkpoint? >>>>>>>>>> >>>>>>>>>> Best, >>>>>>>>>> Congxian >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> Bekir Oguz <[hidden email]> 于2019年7月16日周二 下午10:45写道: >>>>>>>>>> >>>>>>>>>> Hi all, >>>>>>>>>> We have a flink job with user state, checkpointing to >>>>>>>>>> RocksDBBackend >>>>>>>>>> which is externally stored in AWS S3. >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see >>>>>>>>>> occasionally >>>>>>>>>> that some slots do to acknowledge the checkpoints quick enough. >>>>>>>>>> As an >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except only >>>>>>>>>> one slot >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to each >>>>>>>>>> other, like >>>>>>>>>> 200-400 MB. >>>>>>>>>> >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We have >>>>>>>>>> 5 min >>>>>>>>>> checkpoint interval and this happens sometimes once in an hour >>>>>>>>>> sometimes >>>>>>>>>> more but not in all the checkpoint requests. Please see the >>>>>>>>>> screenshot >>>>>>>>>> below. >>>>>>>>>> >>>>>>>>>> Also another point: For the faulty slots, the duration is >>>>>>>>>> consistently 15 >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 mins >>>>>>>>>> response >>>>>>>>>> time comes from. And each time it is a different task manager, >>>>>>>>>> not always >>>>>>>>>> the same one. >>>>>>>>>> >>>>>>>>>> Do you guys aware of any other users having similar issues with >>>>>>>>>> the new >>>>>>>>>> version and also a suggested bug fix or solution? >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> Thanks in advance, >>>>>>>>>> Bekir Oguz >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>> >>>>>>>> >>>>>>> >>>>>>> >>>>>> >> >> -- >> -- Bekir Oguz >> > |
Re: instable checkpointing after migration to flink 1.8
|
|
Hi all!
A thought would be that this has something to do with timers. Does the task with that behavior use timers (windows, or process function)? If that is the case, some theories to check: - Could it be a timer firing storm coinciding with a checkpoint? Currently, that storm synchronously fires, checkpoints cannot preempt that, which should change in 1.10 with the new mailbox model. - Could the timer-async checkpointing changes have something to do with that? Does some of the usually small "preparation work" (happening synchronously) lead to an unwanted effect? - Are you using TTL for state in that operator? - There were some changes made to support timers in RocksDB recently. Could that have something to do with it? Best, Stephan On Fri, Aug 30, 2019 at 2:45 PM Congxian Qiu <[hidden email]> wrote: > CC flink dev mail list > Update for those who may be interested in this issue, we'are still > diagnosing this problem currently. > > Best, > Congxian > > > Congxian Qiu <[hidden email]> 于2019年8月29日周四 下午8:58写道: > > > Hi Bekir > > > > Currently, from what we have diagnosed, there is some task complete its > > checkpoint too late (maybe 15 mins), but we checked the kafka broker log > > and did not find any interesting things there. could we run another job, > > that did not commit offset to kafka, this wants to check if it is the > > "commit offset to kafka" step consumes too much time. > > > > Best, > > Congxian > > > > > > Bekir Oguz <[hidden email]> 于2019年8月28日周三 下午4:19写道: > > > >> Hi Congxian, > >> sorry for the late reply, but no progress on this issue yet. I checked > >> also the kafka broker logs, found nothing interesting there. > >> And we still have 15 min duration checkpoints quite often. Any more > ideas > >> on where to look at? > >> > >> Regards, > >> Bekir > >> > >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email]> > >> wrote: > >> > >>> Hi Bekir > >>> > >>> Do you come back to work now, does there any more findings of this > >>> problem? > >>> > >>> Best, > >>> Congxian > >>> > >>> > >>> Bekir Oguz <[hidden email]> 于2019年8月13日周二 下午4:39写道: > >>> > >>>> Hi Congxian, > >>>> Thanks for following up this issue. It is still unresolved and I am on > >>>> vacation at the moment. Hopefully my collegues Niels and Vlad can > spare > >>>> some time to look into this. > >>>> > >>>> @Niels, @Vlad: do you guys also think that this issue might be Kafka > >>>> related? We could also check kafka broker logs at the time of long > >>>> checkpointing. > >>>> > >>>> Thanks, > >>>> Bekir > >>>> > >>>> Verstuurd vanaf mijn iPhone > >>>> > >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu <[hidden email]> > >>>> het volgende geschreven: > >>>> > >>>> Hi Bekir > >>>> > >>>> Is there any progress about this problem? > >>>> > >>>> Best, > >>>> Congxian > >>>> > >>>> > >>>> Congxian Qiu <[hidden email]> 于2019年8月8日周四 下午11:17写道: > >>>> > >>>>> hi Bekir > >>>>> Thanks for the information. > >>>>> > >>>>> - Source's checkpoint was triggered by RPC calls, so it has the > >>>>> "Trigger checkpoint xxx" log, > >>>>> - other task's checkpoint was triggered after received all the > barrier > >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( > >>>>> > >>>>> Your diagnose makes sense to me, we need to check the Kafka log. > >>>>> I also find out that we always have a log like > >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator > Marking > >>>>> the coordinator 172.19.200.73:9092 (id: 2147483646 rack: null) dead > >>>>> for group userprofileaggregator > >>>>> 2019-08-06 13:58:49,872 DEBUG > >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - > Notifica", > >>>>> > >>>>> I checked the doc of kafka[1], only find that the default of ` > >>>>> transaction.max.timeout.ms` is 15 min > >>>>> > >>>>> Please let me know there you have any finds. thanks > >>>>> > >>>>> PS: maybe you can also checkpoint the log for task > >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message late > also. > >>>>> > >>>>> [1] https://kafka.apache.org/documentation/ > >>>>> Best, > >>>>> Congxian > >>>>> > >>>>> > >>>>> Bekir Oguz <[hidden email]> 于2019年8月7日周三 下午6:48写道: > >>>>> > >>>>>> Hi Congxian, > >>>>>> Thanks for checking the logs. What I see from the logs is: > >>>>>> > >>>>>> - For the tasks like "Source: > >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” {17, > 27, 31, > >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also ‘Confirm > >>>>>> checkpoint’ log lines, with 15 mins delay in between. > >>>>>> - For the tasks like “KeyedProcess -> (Sink: > >>>>>> profileservice-userprofiles_kafka_sink, Sink: > >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: > >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We DO > NOT have > >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm checkpoint’ > lines. > >>>>>> > >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator logs > >>>>>> about lost connection to Kafka at the same time we have the > checkpoints > >>>>>> confirmed. This 15 minutes delay might be because of some timeout > at the > >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka > coordinator > >>>>>> dead, and then discovering kafka coordinator again. > >>>>>> > >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot confirm > >>>>>> the checkpoints, cannot send the async offset commit request to > Kafka. This > >>>>>> could be the root cause of the problem. Please see the attached logs > >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a 15 > minutes > >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 and > 9:52) > >>>>>> > >>>>>> > >>>>>> I will enable Kafka DEBUG logging to see more and let you know about > >>>>>> the findings. > >>>>>> > >>>>>> Thanks a lot for your support, > >>>>>> Bekir Oguz > >>>>>> > >>>>>> > >>>>>> > >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu <[hidden email] > > > >>>>>> het volgende geschreven: > >>>>>> > >>>>>> Hi > >>>>>> > >>>>>> Received all the files, as a first glance, the program uses at least > >>>>>> once checkpoint mode, from the tm log, maybe we need to check > checkpoint of > >>>>>> this operator "Invoking async call Checkpoint Confirmation for > KeyedProcess > >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: > >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: > >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task > KeyedProcess -> > >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: > >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: > >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", > >>>>>> > >>>>>> Seems it took too long to complete the checkpoint (maybe something > >>>>>> about itself, or maybe something of Kafka). I'll go through the logs > >>>>>> carefully today or tomorrow again. > >>>>>> > >>>>>> Best, > >>>>>> Congxian > >>>>>> > >>>>>> > >>>>>> Bekir Oguz <[hidden email]> 于2019年8月6日周二 下午10:38写道: > >>>>>> > >>>>>>> Ok, I am removing apache dev group from CC. > >>>>>>> Only sending to you and my colleagues. > >>>>>>> > >>>>>>> > >>>>>>> Thanks, > >>>>>>> Bekir > >>>>>>> > >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz < > [hidden email]> > >>>>>>> het volgende geschreven: > >>>>>>> > >>>>>>> Hi Congxian, > >>>>>>> Previous email didn’t work out due to size limits. > >>>>>>> I am sending you only job manager log zipped, and will send other > >>>>>>> info in separate email. > >>>>>>> <jobmanager_sb77v.log.zip> > >>>>>>> Regards, > >>>>>>> Bekir > >>>>>>> > >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu < > [hidden email]> > >>>>>>> het volgende geschreven: > >>>>>>> > >>>>>>> Hi Bekir > >>>>>>> > >>>>>>> Cloud you please also share the below information: > >>>>>>> - jobmanager.log > >>>>>>> - taskmanager.log(with debug info enabled) for the problematic > >>>>>>> subtask. > >>>>>>> - the DAG of your program (if can provide the skeleton program is > >>>>>>> better -- can send to me privately) > >>>>>>> > >>>>>>> For the subIndex, maybe we can use the deploy log message in > >>>>>>> jobmanager log to identify which subtask we want. For example in > JM log, > >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO > >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - Deploying > Source: > >>>>>>> Custom Source (2/2) (attempt #0) to > >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee > >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was deplyed > to " > >>>>>>> aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still more > than > >>>>>>> one subtasks in one contain :( > >>>>>>> > >>>>>>> Best, > >>>>>>> Congxian > >>>>>>> > >>>>>>> > >>>>>>> Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道: > >>>>>>> > >>>>>>>> Forgot to add the checkpoint details after it was complete. This > is > >>>>>>>> for that long running checkpoint with id 95632. > >>>>>>>> > >>>>>>>> <PastedGraphic-5.png> > >>>>>>>> > >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz < > [hidden email]> > >>>>>>>> het volgende geschreven: > >>>>>>>> > >>>>>>>> Hi Congxian, > >>>>>>>> I was able to fetch the logs of the task manager (attached) and > the > >>>>>>>> screenshots of the latest long checkpoint. I will get the logs of > the job > >>>>>>>> manager for the next long running checkpoint. And also I will try > to get a > >>>>>>>> jstack during the long running checkpoint. > >>>>>>>> > >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask > numbers, > >>>>>>>> and at the Details tab of the checkpoint, we have the subtask > numbers but > >>>>>>>> not the task manager hosts, it is difficult to match those. We’re > assuming > >>>>>>>> they have the same order, so seeing that 3rd subtask is failing, > I am > >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the task > manager > >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a great > feature if > >>>>>>>> you guys also include the subtask-id’s to the Subtasks view.*** > >>>>>>>> > >>>>>>>> Note: timestamps in the task manager log are in UTC and I am at > the > >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot matches > the time > >>>>>>>> 7:30 in the log. > >>>>>>>> > >>>>>>>> > >>>>>>>> Kind regards, > >>>>>>>> Bekir > >>>>>>>> > >>>>>>>> <task_manager.log> > >>>>>>>> > >>>>>>>> <PastedGraphic-4.png> > >>>>>>>> <PastedGraphic-3.png> > >>>>>>>> <PastedGraphic-2.png> > >>>>>>>> > >>>>>>>> > >>>>>>>> > >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu < > [hidden email]> > >>>>>>>> het volgende geschreven: > >>>>>>>> > >>>>>>>> Hi Bekir > >>>>>>>> I’ll first summary the problem here(please correct me if I’m > wrong) > >>>>>>>> 1. The same program runs on 1.6 never encounter such problems > >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other normal > >>>>>>>> checkpoints complete less than 1 min > >>>>>>>> 3. Some bad checkpoint will have a large sync time, async time > >>>>>>>> seems ok > >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger than > >>>>>>>> (sync_time + async_time) > >>>>>>>> First, answer the last question, the e2e duration is ack_time - > >>>>>>>> trigger_time, so it always bigger than (sync_time + async_time), > but we > >>>>>>>> have a big gap here, this may be problematic. > >>>>>>>> According to all the information, maybe the problem is some task > >>>>>>>> start to do checkpoint too late and the sync checkpoint part took > some time > >>>>>>>> too long, Could you please share some more information such below: > >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A > here) > >>>>>>>> - The detailed information of checkpoint A(includes all the > >>>>>>>> problematic subtasks) > >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic task > >>>>>>>> and a health task > >>>>>>>> - Share the screenshot of subtasks for the problematic > >>>>>>>> task(includes the `Bytes received`, `Records received`, `Bytes > sent`, > >>>>>>>> `Records sent` column), here wants to compare the problematic > parallelism > >>>>>>>> and good parallelism’s information, please also share the > information is > >>>>>>>> there has a data skew among the parallelisms, > >>>>>>>> - could you please share some jstacks of the problematic > >>>>>>>> parallelism — here wants to check whether the task is too busy to > handle > >>>>>>>> the barrier. (flame graph or other things is always welcome here) > >>>>>>>> > >>>>>>>> Best, > >>>>>>>> Congxian > >>>>>>>> > >>>>>>>> > >>>>>>>> Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道: > >>>>>>>> > >>>>>>>>> Hi Bekir > >>>>>>>>> > >>>>>>>>> I'll first comb through all the information here, and try to find > >>>>>>>>> out the reason with you, maybe need you to share some more > information :) > >>>>>>>>> > >>>>>>>>> Best, > >>>>>>>>> Congxian > >>>>>>>>> > >>>>>>>>> > >>>>>>>>> Bekir Oguz <[hidden email]> 于2019年8月1日周四 下午5:00写道: > >>>>>>>>> > >>>>>>>>>> Hi Fabian, > >>>>>>>>>> Thanks for sharing this with us, but we’re already on version > >>>>>>>>>> 1.8.1. > >>>>>>>>>> > >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 > >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you maybe > give us some > >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 > minutes defined > >>>>>>>>>> somewhere in Flink? I couldn’t find one. > >>>>>>>>>> > >>>>>>>>>> In our pipeline, most of the checkpoints complete in less than a > >>>>>>>>>> minute and some of them completed in 15 minutes+(less than a > minute). > >>>>>>>>>> There’s definitely something which adds 15 minutes. This is > >>>>>>>>>> happening in one or more subtasks during checkpointing. > >>>>>>>>>> > >>>>>>>>>> Please see the screenshot below: > >>>>>>>>>> > >>>>>>>>>> Regards, > >>>>>>>>>> Bekir > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske < > [hidden email]> > >>>>>>>>>> het volgende geschreven: > >>>>>>>>>> > >>>>>>>>>> Hi Bekir, > >>>>>>>>>> > >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 [1]. > >>>>>>>>>> These seem to be resolved with Flink 1.8.1. > >>>>>>>>>> > >>>>>>>>>> Hope this helps, > >>>>>>>>>> Fabian > >>>>>>>>>> > >>>>>>>>>> [1] > >>>>>>>>>> > >>>>>>>>>> > https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E > >>>>>>>>>> > >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < > >>>>>>>>>> [hidden email]>: > >>>>>>>>>> > >>>>>>>>>> Hi Bekir > >>>>>>>>>> > >>>>>>>>>> First of all, I think there is something wrong. the state size > >>>>>>>>>> is almost > >>>>>>>>>> the same, but the duration is different so much. > >>>>>>>>>> > >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, then > >>>>>>>>>> copy the > >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the sst > >>>>>>>>>> files > >>>>>>>>>> already on remote will not upload), then complete checkpoint. > Can > >>>>>>>>>> you check > >>>>>>>>>> the network bandwidth usage during checkpoint? > >>>>>>>>>> > >>>>>>>>>> Best, > >>>>>>>>>> Congxian > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> Bekir Oguz <[hidden email]> 于2019年7月16日周二 下午10:45写道: > >>>>>>>>>> > >>>>>>>>>> Hi all, > >>>>>>>>>> We have a flink job with user state, checkpointing to > >>>>>>>>>> RocksDBBackend > >>>>>>>>>> which is externally stored in AWS S3. > >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see > >>>>>>>>>> occasionally > >>>>>>>>>> that some slots do to acknowledge the checkpoints quick enough. > >>>>>>>>>> As an > >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except only > >>>>>>>>>> one slot > >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to each > >>>>>>>>>> other, like > >>>>>>>>>> 200-400 MB. > >>>>>>>>>> > >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We have > >>>>>>>>>> 5 min > >>>>>>>>>> checkpoint interval and this happens sometimes once in an hour > >>>>>>>>>> sometimes > >>>>>>>>>> more but not in all the checkpoint requests. Please see the > >>>>>>>>>> screenshot > >>>>>>>>>> below. > >>>>>>>>>> > >>>>>>>>>> Also another point: For the faulty slots, the duration is > >>>>>>>>>> consistently 15 > >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 mins > >>>>>>>>>> response > >>>>>>>>>> time comes from. And each time it is a different task manager, > >>>>>>>>>> not always > >>>>>>>>>> the same one. > >>>>>>>>>> > >>>>>>>>>> Do you guys aware of any other users having similar issues with > >>>>>>>>>> the new > >>>>>>>>>> version and also a suggested bug fix or solution? > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> Thanks in advance, > >>>>>>>>>> Bekir Oguz > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>> > >>>>>>>> > >>>>>>> > >>>>>>> > >>>>>> > >> > >> -- > >> -- Bekir Oguz > >> > > > |
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Stephan,
sorry for late response. We indeed use timers inside a KeyedProcessFunction but the triggers of the timers are kinda evenly distributed, so not causing a firing storm. We have a custom ttl logic which is used by the deletion timer to decide whether delete a record from inmemory state or not. Can you maybe give some links to those changes in the RocksDB? Thanks in advance, Bekir Oguz On Fri, 30 Aug 2019 at 14:56, Stephan Ewen <[hidden email]> wrote: > Hi all! > > A thought would be that this has something to do with timers. Does the > task with that behavior use timers (windows, or process function)? > > If that is the case, some theories to check: > - Could it be a timer firing storm coinciding with a checkpoint? > Currently, that storm synchronously fires, checkpoints cannot preempt that, > which should change in 1.10 with the new mailbox model. > - Could the timer-async checkpointing changes have something to do with > that? Does some of the usually small "preparation work" (happening > synchronously) lead to an unwanted effect? > - Are you using TTL for state in that operator? > - There were some changes made to support timers in RocksDB recently. > Could that have something to do with it? > > Best, > Stephan > > > On Fri, Aug 30, 2019 at 2:45 PM Congxian Qiu <[hidden email]> > wrote: > >> CC flink dev mail list >> Update for those who may be interested in this issue, we'are still >> diagnosing this problem currently. >> >> Best, >> Congxian >> >> >> Congxian Qiu <[hidden email]> 于2019年8月29日周四 下午8:58写道: >> >> > Hi Bekir >> > >> > Currently, from what we have diagnosed, there is some task complete its >> > checkpoint too late (maybe 15 mins), but we checked the kafka broker log >> > and did not find any interesting things there. could we run another job, >> > that did not commit offset to kafka, this wants to check if it is the >> > "commit offset to kafka" step consumes too much time. >> > >> > Best, >> > Congxian >> > >> > >> > Bekir Oguz <[hidden email]> 于2019年8月28日周三 下午4:19写道: >> > >> >> Hi Congxian, >> >> sorry for the late reply, but no progress on this issue yet. I checked >> >> also the kafka broker logs, found nothing interesting there. >> >> And we still have 15 min duration checkpoints quite often. Any more >> ideas >> >> on where to look at? >> >> >> >> Regards, >> >> Bekir >> >> >> >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email]> >> >> wrote: >> >> >> >>> Hi Bekir >> >>> >> >>> Do you come back to work now, does there any more findings of this >> >>> problem? >> >>> >> >>> Best, >> >>> Congxian >> >>> >> >>> >> >>> Bekir Oguz <[hidden email]> 于2019年8月13日周二 下午4:39写道: >> >>> >> >>>> Hi Congxian, >> >>>> Thanks for following up this issue. It is still unresolved and I am >> on >> >>>> vacation at the moment. Hopefully my collegues Niels and Vlad can >> spare >> >>>> some time to look into this. >> >>>> >> >>>> @Niels, @Vlad: do you guys also think that this issue might be Kafka >> >>>> related? We could also check kafka broker logs at the time of long >> >>>> checkpointing. >> >>>> >> >>>> Thanks, >> >>>> Bekir >> >>>> >> >>>> Verstuurd vanaf mijn iPhone >> >>>> >> >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu <[hidden email]> >> >>>> het volgende geschreven: >> >>>> >> >>>> Hi Bekir >> >>>> >> >>>> Is there any progress about this problem? >> >>>> >> >>>> Best, >> >>>> Congxian >> >>>> >> >>>> >> >>>> Congxian Qiu <[hidden email]> 于2019年8月8日周四 下午11:17写道: >> >>>> >> >>>>> hi Bekir >> >>>>> Thanks for the information. >> >>>>> >> >>>>> - Source's checkpoint was triggered by RPC calls, so it has the >> >>>>> "Trigger checkpoint xxx" log, >> >>>>> - other task's checkpoint was triggered after received all the >> barrier >> >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( >> >>>>> >> >>>>> Your diagnose makes sense to me, we need to check the Kafka log. >> >>>>> I also find out that we always have a log like >> >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator >> Marking >> >>>>> the coordinator 172.19.200.73:9092 (id: 2147483646 rack: null) dead >> >>>>> for group userprofileaggregator >> >>>>> 2019-08-06 13:58:49,872 DEBUG >> >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - >> Notifica", >> >>>>> >> >>>>> I checked the doc of kafka[1], only find that the default of ` >> >>>>> transaction.max.timeout.ms` is 15 min >> >>>>> >> >>>>> Please let me know there you have any finds. thanks >> >>>>> >> >>>>> PS: maybe you can also checkpoint the log for task >> >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message >> late also. >> >>>>> >> >>>>> [1] https://kafka.apache.org/documentation/ >> >>>>> Best, >> >>>>> Congxian >> >>>>> >> >>>>> >> >>>>> Bekir Oguz <[hidden email]> 于2019年8月7日周三 下午6:48写道: >> >>>>> >> >>>>>> Hi Congxian, >> >>>>>> Thanks for checking the logs. What I see from the logs is: >> >>>>>> >> >>>>>> - For the tasks like "Source: >> >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” {17, >> 27, 31, >> >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also >> ‘Confirm >> >>>>>> checkpoint’ log lines, with 15 mins delay in between. >> >>>>>> - For the tasks like “KeyedProcess -> (Sink: >> >>>>>> profileservice-userprofiles_kafka_sink, Sink: >> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >> >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We DO >> NOT have >> >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm checkpoint’ >> lines. >> >>>>>> >> >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator logs >> >>>>>> about lost connection to Kafka at the same time we have the >> checkpoints >> >>>>>> confirmed. This 15 minutes delay might be because of some timeout >> at the >> >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka >> coordinator >> >>>>>> dead, and then discovering kafka coordinator again. >> >>>>>> >> >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot >> confirm >> >>>>>> the checkpoints, cannot send the async offset commit request to >> Kafka. This >> >>>>>> could be the root cause of the problem. Please see the attached >> logs >> >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a 15 >> minutes >> >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 and >> 9:52) >> >>>>>> >> >>>>>> >> >>>>>> I will enable Kafka DEBUG logging to see more and let you know >> about >> >>>>>> the findings. >> >>>>>> >> >>>>>> Thanks a lot for your support, >> >>>>>> Bekir Oguz >> >>>>>> >> >>>>>> >> >>>>>> >> >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu < >> [hidden email]> >> >>>>>> het volgende geschreven: >> >>>>>> >> >>>>>> Hi >> >>>>>> >> >>>>>> Received all the files, as a first glance, the program uses at >> least >> >>>>>> once checkpoint mode, from the tm log, maybe we need to check >> checkpoint of >> >>>>>> this operator "Invoking async call Checkpoint Confirmation for >> KeyedProcess >> >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: >> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task >> KeyedProcess -> >> >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: >> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", >> >>>>>> >> >>>>>> Seems it took too long to complete the checkpoint (maybe something >> >>>>>> about itself, or maybe something of Kafka). I'll go through the >> logs >> >>>>>> carefully today or tomorrow again. >> >>>>>> >> >>>>>> Best, >> >>>>>> Congxian >> >>>>>> >> >>>>>> >> >>>>>> Bekir Oguz <[hidden email]> 于2019年8月6日周二 下午10:38写道: >> >>>>>> >> >>>>>>> Ok, I am removing apache dev group from CC. >> >>>>>>> Only sending to you and my colleagues. >> >>>>>>> >> >>>>>>> >> >>>>>>> Thanks, >> >>>>>>> Bekir >> >>>>>>> >> >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz < >> [hidden email]> >> >>>>>>> het volgende geschreven: >> >>>>>>> >> >>>>>>> Hi Congxian, >> >>>>>>> Previous email didn’t work out due to size limits. >> >>>>>>> I am sending you only job manager log zipped, and will send other >> >>>>>>> info in separate email. >> >>>>>>> <jobmanager_sb77v.log.zip> >> >>>>>>> Regards, >> >>>>>>> Bekir >> >>>>>>> >> >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu < >> [hidden email]> >> >>>>>>> het volgende geschreven: >> >>>>>>> >> >>>>>>> Hi Bekir >> >>>>>>> >> >>>>>>> Cloud you please also share the below information: >> >>>>>>> - jobmanager.log >> >>>>>>> - taskmanager.log(with debug info enabled) for the problematic >> >>>>>>> subtask. >> >>>>>>> - the DAG of your program (if can provide the skeleton program is >> >>>>>>> better -- can send to me privately) >> >>>>>>> >> >>>>>>> For the subIndex, maybe we can use the deploy log message in >> >>>>>>> jobmanager log to identify which subtask we want. For example in >> JM log, >> >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO >> >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - >> Deploying Source: >> >>>>>>> Custom Source (2/2) (attempt #0) to >> >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee >> >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was deplyed >> to " >> >>>>>>> aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still more >> than >> >>>>>>> one subtasks in one contain :( >> >>>>>>> >> >>>>>>> Best, >> >>>>>>> Congxian >> >>>>>>> >> >>>>>>> >> >>>>>>> Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道: >> >>>>>>> >> >>>>>>>> Forgot to add the checkpoint details after it was complete. This >> is >> >>>>>>>> for that long running checkpoint with id 95632. >> >>>>>>>> >> >>>>>>>> <PastedGraphic-5.png> >> >>>>>>>> >> >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz < >> [hidden email]> >> >>>>>>>> het volgende geschreven: >> >>>>>>>> >> >>>>>>>> Hi Congxian, >> >>>>>>>> I was able to fetch the logs of the task manager (attached) and >> the >> >>>>>>>> screenshots of the latest long checkpoint. I will get the logs >> of the job >> >>>>>>>> manager for the next long running checkpoint. And also I will >> try to get a >> >>>>>>>> jstack during the long running checkpoint. >> >>>>>>>> >> >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask >> numbers, >> >>>>>>>> and at the Details tab of the checkpoint, we have the subtask >> numbers but >> >>>>>>>> not the task manager hosts, it is difficult to match those. >> We’re assuming >> >>>>>>>> they have the same order, so seeing that 3rd subtask is failing, >> I am >> >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the task >> manager >> >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a great >> feature if >> >>>>>>>> you guys also include the subtask-id’s to the Subtasks view.*** >> >>>>>>>> >> >>>>>>>> Note: timestamps in the task manager log are in UTC and I am at >> the >> >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot >> matches the time >> >>>>>>>> 7:30 in the log. >> >>>>>>>> >> >>>>>>>> >> >>>>>>>> Kind regards, >> >>>>>>>> Bekir >> >>>>>>>> >> >>>>>>>> <task_manager.log> >> >>>>>>>> >> >>>>>>>> <PastedGraphic-4.png> >> >>>>>>>> <PastedGraphic-3.png> >> >>>>>>>> <PastedGraphic-2.png> >> >>>>>>>> >> >>>>>>>> >> >>>>>>>> >> >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu < >> [hidden email]> >> >>>>>>>> het volgende geschreven: >> >>>>>>>> >> >>>>>>>> Hi Bekir >> >>>>>>>> I’ll first summary the problem here(please correct me if I’m >> wrong) >> >>>>>>>> 1. The same program runs on 1.6 never encounter such problems >> >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other >> normal >> >>>>>>>> checkpoints complete less than 1 min >> >>>>>>>> 3. Some bad checkpoint will have a large sync time, async time >> >>>>>>>> seems ok >> >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger than >> >>>>>>>> (sync_time + async_time) >> >>>>>>>> First, answer the last question, the e2e duration is ack_time - >> >>>>>>>> trigger_time, so it always bigger than (sync_time + async_time), >> but we >> >>>>>>>> have a big gap here, this may be problematic. >> >>>>>>>> According to all the information, maybe the problem is some task >> >>>>>>>> start to do checkpoint too late and the sync checkpoint part >> took some time >> >>>>>>>> too long, Could you please share some more information such >> below: >> >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A >> here) >> >>>>>>>> - The detailed information of checkpoint A(includes all the >> >>>>>>>> problematic subtasks) >> >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic task >> >>>>>>>> and a health task >> >>>>>>>> - Share the screenshot of subtasks for the problematic >> >>>>>>>> task(includes the `Bytes received`, `Records received`, `Bytes >> sent`, >> >>>>>>>> `Records sent` column), here wants to compare the problematic >> parallelism >> >>>>>>>> and good parallelism’s information, please also share the >> information is >> >>>>>>>> there has a data skew among the parallelisms, >> >>>>>>>> - could you please share some jstacks of the problematic >> >>>>>>>> parallelism — here wants to check whether the task is too busy >> to handle >> >>>>>>>> the barrier. (flame graph or other things is always welcome here) >> >>>>>>>> >> >>>>>>>> Best, >> >>>>>>>> Congxian >> >>>>>>>> >> >>>>>>>> >> >>>>>>>> Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道: >> >>>>>>>> >> >>>>>>>>> Hi Bekir >> >>>>>>>>> >> >>>>>>>>> I'll first comb through all the information here, and try to >> find >> >>>>>>>>> out the reason with you, maybe need you to share some more >> information :) >> >>>>>>>>> >> >>>>>>>>> Best, >> >>>>>>>>> Congxian >> >>>>>>>>> >> >>>>>>>>> >> >>>>>>>>> Bekir Oguz <[hidden email]> 于2019年8月1日周四 下午5:00写道: >> >>>>>>>>> >> >>>>>>>>>> Hi Fabian, >> >>>>>>>>>> Thanks for sharing this with us, but we’re already on version >> >>>>>>>>>> 1.8.1. >> >>>>>>>>>> >> >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 >> >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you maybe >> give us some >> >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 >> minutes defined >> >>>>>>>>>> somewhere in Flink? I couldn’t find one. >> >>>>>>>>>> >> >>>>>>>>>> In our pipeline, most of the checkpoints complete in less than >> a >> >>>>>>>>>> minute and some of them completed in 15 minutes+(less than a >> minute). >> >>>>>>>>>> There’s definitely something which adds 15 minutes. This is >> >>>>>>>>>> happening in one or more subtasks during checkpointing. >> >>>>>>>>>> >> >>>>>>>>>> Please see the screenshot below: >> >>>>>>>>>> >> >>>>>>>>>> Regards, >> >>>>>>>>>> Bekir >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske < >> [hidden email]> >> >>>>>>>>>> het volgende geschreven: >> >>>>>>>>>> >> >>>>>>>>>> Hi Bekir, >> >>>>>>>>>> >> >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 >> [1]. >> >>>>>>>>>> These seem to be resolved with Flink 1.8.1. >> >>>>>>>>>> >> >>>>>>>>>> Hope this helps, >> >>>>>>>>>> Fabian >> >>>>>>>>>> >> >>>>>>>>>> [1] >> >>>>>>>>>> >> >>>>>>>>>> >> https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E >> >>>>>>>>>> >> >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < >> >>>>>>>>>> [hidden email]>: >> >>>>>>>>>> >> >>>>>>>>>> Hi Bekir >> >>>>>>>>>> >> >>>>>>>>>> First of all, I think there is something wrong. the state size >> >>>>>>>>>> is almost >> >>>>>>>>>> the same, but the duration is different so much. >> >>>>>>>>>> >> >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, then >> >>>>>>>>>> copy the >> >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the sst >> >>>>>>>>>> files >> >>>>>>>>>> already on remote will not upload), then complete checkpoint. >> Can >> >>>>>>>>>> you check >> >>>>>>>>>> the network bandwidth usage during checkpoint? >> >>>>>>>>>> >> >>>>>>>>>> Best, >> >>>>>>>>>> Congxian >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> Bekir Oguz <[hidden email]> 于2019年7月16日周二 下午10:45写道: >> >>>>>>>>>> >> >>>>>>>>>> Hi all, >> >>>>>>>>>> We have a flink job with user state, checkpointing to >> >>>>>>>>>> RocksDBBackend >> >>>>>>>>>> which is externally stored in AWS S3. >> >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see >> >>>>>>>>>> occasionally >> >>>>>>>>>> that some slots do to acknowledge the checkpoints quick enough. >> >>>>>>>>>> As an >> >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except >> only >> >>>>>>>>>> one slot >> >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to each >> >>>>>>>>>> other, like >> >>>>>>>>>> 200-400 MB. >> >>>>>>>>>> >> >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We >> have >> >>>>>>>>>> 5 min >> >>>>>>>>>> checkpoint interval and this happens sometimes once in an hour >> >>>>>>>>>> sometimes >> >>>>>>>>>> more but not in all the checkpoint requests. Please see the >> >>>>>>>>>> screenshot >> >>>>>>>>>> below. >> >>>>>>>>>> >> >>>>>>>>>> Also another point: For the faulty slots, the duration is >> >>>>>>>>>> consistently 15 >> >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 mins >> >>>>>>>>>> response >> >>>>>>>>>> time comes from. And each time it is a different task manager, >> >>>>>>>>>> not always >> >>>>>>>>>> the same one. >> >>>>>>>>>> >> >>>>>>>>>> Do you guys aware of any other users having similar issues with >> >>>>>>>>>> the new >> >>>>>>>>>> version and also a suggested bug fix or solution? >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> Thanks in advance, >> >>>>>>>>>> Bekir Oguz >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>>>> >> >>>>>>>> >> >>>>>>>> >> >>>>>>> >> >>>>>>> >> >>>>>> >> >> >> >> -- >> >> -- Bekir Oguz >> >> >> > >> > -- -- Bekir Oguz |
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Bekir,
If it is the storage place for timers, for RocksDBStateBackend, timers can be stored in Heap or RocksDB[1][2] [1] https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/large_state_tuning.html#tuning-rocksdb [2] https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/state_backends.html#rocksdb-state-backend-config-options Best, Congxian Bekir Oguz <[hidden email]> 于2019年9月4日周三 下午11:38写道: > Hi Stephan, > sorry for late response. > We indeed use timers inside a KeyedProcessFunction but the triggers of the > timers are kinda evenly distributed, so not causing a firing storm. > We have a custom ttl logic which is used by the deletion timer to decide > whether delete a record from inmemory state or not. > Can you maybe give some links to those changes in the RocksDB? > > Thanks in advance, > Bekir Oguz > > On Fri, 30 Aug 2019 at 14:56, Stephan Ewen <[hidden email]> wrote: > >> Hi all! >> >> A thought would be that this has something to do with timers. Does the >> task with that behavior use timers (windows, or process function)? >> >> If that is the case, some theories to check: >> - Could it be a timer firing storm coinciding with a checkpoint? >> Currently, that storm synchronously fires, checkpoints cannot preempt that, >> which should change in 1.10 with the new mailbox model. >> - Could the timer-async checkpointing changes have something to do with >> that? Does some of the usually small "preparation work" (happening >> synchronously) lead to an unwanted effect? >> - Are you using TTL for state in that operator? >> - There were some changes made to support timers in RocksDB recently. >> Could that have something to do with it? >> >> Best, >> Stephan >> >> >> On Fri, Aug 30, 2019 at 2:45 PM Congxian Qiu <[hidden email]> >> wrote: >> >>> CC flink dev mail list >>> Update for those who may be interested in this issue, we'are still >>> diagnosing this problem currently. >>> >>> Best, >>> Congxian >>> >>> >>> Congxian Qiu <[hidden email]> 于2019年8月29日周四 下午8:58写道: >>> >>> > Hi Bekir >>> > >>> > Currently, from what we have diagnosed, there is some task complete its >>> > checkpoint too late (maybe 15 mins), but we checked the kafka broker >>> log >>> > and did not find any interesting things there. could we run another >>> job, >>> > that did not commit offset to kafka, this wants to check if it is the >>> > "commit offset to kafka" step consumes too much time. >>> > >>> > Best, >>> > Congxian >>> > >>> > >>> > Bekir Oguz <[hidden email]> 于2019年8月28日周三 下午4:19写道: >>> > >>> >> Hi Congxian, >>> >> sorry for the late reply, but no progress on this issue yet. I checked >>> >> also the kafka broker logs, found nothing interesting there. >>> >> And we still have 15 min duration checkpoints quite often. Any more >>> ideas >>> >> on where to look at? >>> >> >>> >> Regards, >>> >> Bekir >>> >> >>> >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email]> >>> >> wrote: >>> >> >>> >>> Hi Bekir >>> >>> >>> >>> Do you come back to work now, does there any more findings of this >>> >>> problem? >>> >>> >>> >>> Best, >>> >>> Congxian >>> >>> >>> >>> >>> >>> Bekir Oguz <[hidden email]> 于2019年8月13日周二 下午4:39写道: >>> >>> >>> >>>> Hi Congxian, >>> >>>> Thanks for following up this issue. It is still unresolved and I am >>> on >>> >>>> vacation at the moment. Hopefully my collegues Niels and Vlad can >>> spare >>> >>>> some time to look into this. >>> >>>> >>> >>>> @Niels, @Vlad: do you guys also think that this issue might be Kafka >>> >>>> related? We could also check kafka broker logs at the time of long >>> >>>> checkpointing. >>> >>>> >>> >>>> Thanks, >>> >>>> Bekir >>> >>>> >>> >>>> Verstuurd vanaf mijn iPhone >>> >>>> >>> >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu <[hidden email] >>> > >>> >>>> het volgende geschreven: >>> >>>> >>> >>>> Hi Bekir >>> >>>> >>> >>>> Is there any progress about this problem? >>> >>>> >>> >>>> Best, >>> >>>> Congxian >>> >>>> >>> >>>> >>> >>>> Congxian Qiu <[hidden email]> 于2019年8月8日周四 下午11:17写道: >>> >>>> >>> >>>>> hi Bekir >>> >>>>> Thanks for the information. >>> >>>>> >>> >>>>> - Source's checkpoint was triggered by RPC calls, so it has the >>> >>>>> "Trigger checkpoint xxx" log, >>> >>>>> - other task's checkpoint was triggered after received all the >>> barrier >>> >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( >>> >>>>> >>> >>>>> Your diagnose makes sense to me, we need to check the Kafka log. >>> >>>>> I also find out that we always have a log like >>> >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator >>> Marking >>> >>>>> the coordinator 172.19.200.73:9092 (id: 2147483646 rack: null) >>> dead >>> >>>>> for group userprofileaggregator >>> >>>>> 2019-08-06 13:58:49,872 DEBUG >>> >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - >>> Notifica", >>> >>>>> >>> >>>>> I checked the doc of kafka[1], only find that the default of ` >>> >>>>> transaction.max.timeout.ms` is 15 min >>> >>>>> >>> >>>>> Please let me know there you have any finds. thanks >>> >>>>> >>> >>>>> PS: maybe you can also checkpoint the log for task >>> >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message >>> late also. >>> >>>>> >>> >>>>> [1] https://kafka.apache.org/documentation/ >>> >>>>> Best, >>> >>>>> Congxian >>> >>>>> >>> >>>>> >>> >>>>> Bekir Oguz <[hidden email]> 于2019年8月7日周三 下午6:48写道: >>> >>>>> >>> >>>>>> Hi Congxian, >>> >>>>>> Thanks for checking the logs. What I see from the logs is: >>> >>>>>> >>> >>>>>> - For the tasks like "Source: >>> >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” {17, >>> 27, 31, >>> >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also >>> ‘Confirm >>> >>>>>> checkpoint’ log lines, with 15 mins delay in between. >>> >>>>>> - For the tasks like “KeyedProcess -> (Sink: >>> >>>>>> profileservice-userprofiles_kafka_sink, Sink: >>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>> >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We DO >>> NOT have >>> >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm >>> checkpoint’ lines. >>> >>>>>> >>> >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator >>> logs >>> >>>>>> about lost connection to Kafka at the same time we have the >>> checkpoints >>> >>>>>> confirmed. This 15 minutes delay might be because of some timeout >>> at the >>> >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka >>> coordinator >>> >>>>>> dead, and then discovering kafka coordinator again. >>> >>>>>> >>> >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot >>> confirm >>> >>>>>> the checkpoints, cannot send the async offset commit request to >>> Kafka. This >>> >>>>>> could be the root cause of the problem. Please see the attached >>> logs >>> >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a >>> 15 minutes >>> >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 and >>> 9:52) >>> >>>>>> >>> >>>>>> >>> >>>>>> I will enable Kafka DEBUG logging to see more and let you know >>> about >>> >>>>>> the findings. >>> >>>>>> >>> >>>>>> Thanks a lot for your support, >>> >>>>>> Bekir Oguz >>> >>>>>> >>> >>>>>> >>> >>>>>> >>> >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu < >>> [hidden email]> >>> >>>>>> het volgende geschreven: >>> >>>>>> >>> >>>>>> Hi >>> >>>>>> >>> >>>>>> Received all the files, as a first glance, the program uses at >>> least >>> >>>>>> once checkpoint mode, from the tm log, maybe we need to check >>> checkpoint of >>> >>>>>> this operator "Invoking async call Checkpoint Confirmation for >>> KeyedProcess >>> >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task >>> KeyedProcess -> >>> >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", >>> >>>>>> >>> >>>>>> Seems it took too long to complete the checkpoint (maybe something >>> >>>>>> about itself, or maybe something of Kafka). I'll go through the >>> logs >>> >>>>>> carefully today or tomorrow again. >>> >>>>>> >>> >>>>>> Best, >>> >>>>>> Congxian >>> >>>>>> >>> >>>>>> >>> >>>>>> Bekir Oguz <[hidden email]> 于2019年8月6日周二 下午10:38写道: >>> >>>>>> >>> >>>>>>> Ok, I am removing apache dev group from CC. >>> >>>>>>> Only sending to you and my colleagues. >>> >>>>>>> >>> >>>>>>> >>> >>>>>>> Thanks, >>> >>>>>>> Bekir >>> >>>>>>> >>> >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz < >>> [hidden email]> >>> >>>>>>> het volgende geschreven: >>> >>>>>>> >>> >>>>>>> Hi Congxian, >>> >>>>>>> Previous email didn’t work out due to size limits. >>> >>>>>>> I am sending you only job manager log zipped, and will send other >>> >>>>>>> info in separate email. >>> >>>>>>> <jobmanager_sb77v.log.zip> >>> >>>>>>> Regards, >>> >>>>>>> Bekir >>> >>>>>>> >>> >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu < >>> [hidden email]> >>> >>>>>>> het volgende geschreven: >>> >>>>>>> >>> >>>>>>> Hi Bekir >>> >>>>>>> >>> >>>>>>> Cloud you please also share the below information: >>> >>>>>>> - jobmanager.log >>> >>>>>>> - taskmanager.log(with debug info enabled) for the problematic >>> >>>>>>> subtask. >>> >>>>>>> - the DAG of your program (if can provide the skeleton program is >>> >>>>>>> better -- can send to me privately) >>> >>>>>>> >>> >>>>>>> For the subIndex, maybe we can use the deploy log message in >>> >>>>>>> jobmanager log to identify which subtask we want. For example in >>> JM log, >>> >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO >>> >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - >>> Deploying Source: >>> >>>>>>> Custom Source (2/2) (attempt #0) to >>> >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee >>> >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was deplyed >>> to " >>> >>>>>>> aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still more >>> than >>> >>>>>>> one subtasks in one contain :( >>> >>>>>>> >>> >>>>>>> Best, >>> >>>>>>> Congxian >>> >>>>>>> >>> >>>>>>> >>> >>>>>>> Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道: >>> >>>>>>> >>> >>>>>>>> Forgot to add the checkpoint details after it was complete. >>> This is >>> >>>>>>>> for that long running checkpoint with id 95632. >>> >>>>>>>> >>> >>>>>>>> <PastedGraphic-5.png> >>> >>>>>>>> >>> >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz < >>> [hidden email]> >>> >>>>>>>> het volgende geschreven: >>> >>>>>>>> >>> >>>>>>>> Hi Congxian, >>> >>>>>>>> I was able to fetch the logs of the task manager (attached) and >>> the >>> >>>>>>>> screenshots of the latest long checkpoint. I will get the logs >>> of the job >>> >>>>>>>> manager for the next long running checkpoint. And also I will >>> try to get a >>> >>>>>>>> jstack during the long running checkpoint. >>> >>>>>>>> >>> >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask >>> numbers, >>> >>>>>>>> and at the Details tab of the checkpoint, we have the subtask >>> numbers but >>> >>>>>>>> not the task manager hosts, it is difficult to match those. >>> We’re assuming >>> >>>>>>>> they have the same order, so seeing that 3rd subtask is >>> failing, I am >>> >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the >>> task manager >>> >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a great >>> feature if >>> >>>>>>>> you guys also include the subtask-id’s to the Subtasks view.*** >>> >>>>>>>> >>> >>>>>>>> Note: timestamps in the task manager log are in UTC and I am at >>> the >>> >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot >>> matches the time >>> >>>>>>>> 7:30 in the log. >>> >>>>>>>> >>> >>>>>>>> >>> >>>>>>>> Kind regards, >>> >>>>>>>> Bekir >>> >>>>>>>> >>> >>>>>>>> <task_manager.log> >>> >>>>>>>> >>> >>>>>>>> <PastedGraphic-4.png> >>> >>>>>>>> <PastedGraphic-3.png> >>> >>>>>>>> <PastedGraphic-2.png> >>> >>>>>>>> >>> >>>>>>>> >>> >>>>>>>> >>> >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu < >>> [hidden email]> >>> >>>>>>>> het volgende geschreven: >>> >>>>>>>> >>> >>>>>>>> Hi Bekir >>> >>>>>>>> I’ll first summary the problem here(please correct me if I’m >>> wrong) >>> >>>>>>>> 1. The same program runs on 1.6 never encounter such problems >>> >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other >>> normal >>> >>>>>>>> checkpoints complete less than 1 min >>> >>>>>>>> 3. Some bad checkpoint will have a large sync time, async time >>> >>>>>>>> seems ok >>> >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger than >>> >>>>>>>> (sync_time + async_time) >>> >>>>>>>> First, answer the last question, the e2e duration is ack_time - >>> >>>>>>>> trigger_time, so it always bigger than (sync_time + >>> async_time), but we >>> >>>>>>>> have a big gap here, this may be problematic. >>> >>>>>>>> According to all the information, maybe the problem is some task >>> >>>>>>>> start to do checkpoint too late and the sync checkpoint part >>> took some time >>> >>>>>>>> too long, Could you please share some more information such >>> below: >>> >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A >>> here) >>> >>>>>>>> - The detailed information of checkpoint A(includes all the >>> >>>>>>>> problematic subtasks) >>> >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic >>> task >>> >>>>>>>> and a health task >>> >>>>>>>> - Share the screenshot of subtasks for the problematic >>> >>>>>>>> task(includes the `Bytes received`, `Records received`, `Bytes >>> sent`, >>> >>>>>>>> `Records sent` column), here wants to compare the problematic >>> parallelism >>> >>>>>>>> and good parallelism’s information, please also share the >>> information is >>> >>>>>>>> there has a data skew among the parallelisms, >>> >>>>>>>> - could you please share some jstacks of the problematic >>> >>>>>>>> parallelism — here wants to check whether the task is too busy >>> to handle >>> >>>>>>>> the barrier. (flame graph or other things is always welcome >>> here) >>> >>>>>>>> >>> >>>>>>>> Best, >>> >>>>>>>> Congxian >>> >>>>>>>> >>> >>>>>>>> >>> >>>>>>>> Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道: >>> >>>>>>>> >>> >>>>>>>>> Hi Bekir >>> >>>>>>>>> >>> >>>>>>>>> I'll first comb through all the information here, and try to >>> find >>> >>>>>>>>> out the reason with you, maybe need you to share some more >>> information :) >>> >>>>>>>>> >>> >>>>>>>>> Best, >>> >>>>>>>>> Congxian >>> >>>>>>>>> >>> >>>>>>>>> >>> >>>>>>>>> Bekir Oguz <[hidden email]> 于2019年8月1日周四 下午5:00写道: >>> >>>>>>>>> >>> >>>>>>>>>> Hi Fabian, >>> >>>>>>>>>> Thanks for sharing this with us, but we’re already on version >>> >>>>>>>>>> 1.8.1. >>> >>>>>>>>>> >>> >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 >>> >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you >>> maybe give us some >>> >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 >>> minutes defined >>> >>>>>>>>>> somewhere in Flink? I couldn’t find one. >>> >>>>>>>>>> >>> >>>>>>>>>> In our pipeline, most of the checkpoints complete in less >>> than a >>> >>>>>>>>>> minute and some of them completed in 15 minutes+(less than a >>> minute). >>> >>>>>>>>>> There’s definitely something which adds 15 minutes. This is >>> >>>>>>>>>> happening in one or more subtasks during checkpointing. >>> >>>>>>>>>> >>> >>>>>>>>>> Please see the screenshot below: >>> >>>>>>>>>> >>> >>>>>>>>>> Regards, >>> >>>>>>>>>> Bekir >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske < >>> [hidden email]> >>> >>>>>>>>>> het volgende geschreven: >>> >>>>>>>>>> >>> >>>>>>>>>> Hi Bekir, >>> >>>>>>>>>> >>> >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 >>> [1]. >>> >>>>>>>>>> These seem to be resolved with Flink 1.8.1. >>> >>>>>>>>>> >>> >>>>>>>>>> Hope this helps, >>> >>>>>>>>>> Fabian >>> >>>>>>>>>> >>> >>>>>>>>>> [1] >>> >>>>>>>>>> >>> >>>>>>>>>> >>> https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E >>> >>>>>>>>>> >>> >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < >>> >>>>>>>>>> [hidden email]>: >>> >>>>>>>>>> >>> >>>>>>>>>> Hi Bekir >>> >>>>>>>>>> >>> >>>>>>>>>> First of all, I think there is something wrong. the state >>> size >>> >>>>>>>>>> is almost >>> >>>>>>>>>> the same, but the duration is different so much. >>> >>>>>>>>>> >>> >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, then >>> >>>>>>>>>> copy the >>> >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the sst >>> >>>>>>>>>> files >>> >>>>>>>>>> already on remote will not upload), then complete checkpoint. >>> Can >>> >>>>>>>>>> you check >>> >>>>>>>>>> the network bandwidth usage during checkpoint? >>> >>>>>>>>>> >>> >>>>>>>>>> Best, >>> >>>>>>>>>> Congxian >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> Bekir Oguz <[hidden email]> 于2019年7月16日周二 >>> 下午10:45写道: >>> >>>>>>>>>> >>> >>>>>>>>>> Hi all, >>> >>>>>>>>>> We have a flink job with user state, checkpointing to >>> >>>>>>>>>> RocksDBBackend >>> >>>>>>>>>> which is externally stored in AWS S3. >>> >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see >>> >>>>>>>>>> occasionally >>> >>>>>>>>>> that some slots do to acknowledge the checkpoints quick >>> enough. >>> >>>>>>>>>> As an >>> >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except >>> only >>> >>>>>>>>>> one slot >>> >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to each >>> >>>>>>>>>> other, like >>> >>>>>>>>>> 200-400 MB. >>> >>>>>>>>>> >>> >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We >>> have >>> >>>>>>>>>> 5 min >>> >>>>>>>>>> checkpoint interval and this happens sometimes once in an hour >>> >>>>>>>>>> sometimes >>> >>>>>>>>>> more but not in all the checkpoint requests. Please see the >>> >>>>>>>>>> screenshot >>> >>>>>>>>>> below. >>> >>>>>>>>>> >>> >>>>>>>>>> Also another point: For the faulty slots, the duration is >>> >>>>>>>>>> consistently 15 >>> >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 mins >>> >>>>>>>>>> response >>> >>>>>>>>>> time comes from. And each time it is a different task manager, >>> >>>>>>>>>> not always >>> >>>>>>>>>> the same one. >>> >>>>>>>>>> >>> >>>>>>>>>> Do you guys aware of any other users having similar issues >>> with >>> >>>>>>>>>> the new >>> >>>>>>>>>> version and also a suggested bug fix or solution? >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> Thanks in advance, >>> >>>>>>>>>> Bekir Oguz >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>>>> >>> >>>>>>>> >>> >>>>>>>> >>> >>>>>>> >>> >>>>>>> >>> >>>>>> >>> >> >>> >> -- >>> >> -- Bekir Oguz >>> >> >>> > >>> >> > > -- > -- Bekir Oguz > |
Re: instable checkpointing after migration to flink 1.8
|
|
Another information from our private emails
there ALWAYS have Kafka AbstractCoordinator logs about lost connection to Kafka at the same time we have the checkpoints confirmed. Bekir checked the Kafka broker log, but did not find any interesting things there. Best, Congxian Congxian Qiu <[hidden email]> 于2019年9月5日周四 上午10:26写道: > Hi Bekir, > > If it is the storage place for timers, for RocksDBStateBackend, timers can > be stored in Heap or RocksDB[1][2] > [1] > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/large_state_tuning.html#tuning-rocksdb > [2] > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/state_backends.html#rocksdb-state-backend-config-options > > Best, > Congxian > > > Bekir Oguz <[hidden email]> 于2019年9月4日周三 下午11:38写道: > >> Hi Stephan, >> sorry for late response. >> We indeed use timers inside a KeyedProcessFunction but the triggers of >> the timers are kinda evenly distributed, so not causing a firing storm. >> We have a custom ttl logic which is used by the deletion timer to decide >> whether delete a record from inmemory state or not. >> Can you maybe give some links to those changes in the RocksDB? >> >> Thanks in advance, >> Bekir Oguz >> >> On Fri, 30 Aug 2019 at 14:56, Stephan Ewen <[hidden email]> wrote: >> >>> Hi all! >>> >>> A thought would be that this has something to do with timers. Does the >>> task with that behavior use timers (windows, or process function)? >>> >>> If that is the case, some theories to check: >>> - Could it be a timer firing storm coinciding with a checkpoint? >>> Currently, that storm synchronously fires, checkpoints cannot preempt that, >>> which should change in 1.10 with the new mailbox model. >>> - Could the timer-async checkpointing changes have something to do >>> with that? Does some of the usually small "preparation work" (happening >>> synchronously) lead to an unwanted effect? >>> - Are you using TTL for state in that operator? >>> - There were some changes made to support timers in RocksDB recently. >>> Could that have something to do with it? >>> >>> Best, >>> Stephan >>> >>> >>> On Fri, Aug 30, 2019 at 2:45 PM Congxian Qiu <[hidden email]> >>> wrote: >>> >>>> CC flink dev mail list >>>> Update for those who may be interested in this issue, we'are still >>>> diagnosing this problem currently. >>>> >>>> Best, >>>> Congxian >>>> >>>> >>>> Congxian Qiu <[hidden email]> 于2019年8月29日周四 下午8:58写道: >>>> >>>> > Hi Bekir >>>> > >>>> > Currently, from what we have diagnosed, there is some task complete >>>> its >>>> > checkpoint too late (maybe 15 mins), but we checked the kafka broker >>>> log >>>> > and did not find any interesting things there. could we run another >>>> job, >>>> > that did not commit offset to kafka, this wants to check if it is the >>>> > "commit offset to kafka" step consumes too much time. >>>> > >>>> > Best, >>>> > Congxian >>>> > >>>> > >>>> > Bekir Oguz <[hidden email]> 于2019年8月28日周三 下午4:19写道: >>>> > >>>> >> Hi Congxian, >>>> >> sorry for the late reply, but no progress on this issue yet. I >>>> checked >>>> >> also the kafka broker logs, found nothing interesting there. >>>> >> And we still have 15 min duration checkpoints quite often. Any more >>>> ideas >>>> >> on where to look at? >>>> >> >>>> >> Regards, >>>> >> Bekir >>>> >> >>>> >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email]> >>>> >> wrote: >>>> >> >>>> >>> Hi Bekir >>>> >>> >>>> >>> Do you come back to work now, does there any more findings of this >>>> >>> problem? >>>> >>> >>>> >>> Best, >>>> >>> Congxian >>>> >>> >>>> >>> >>>> >>> Bekir Oguz <[hidden email]> 于2019年8月13日周二 下午4:39写道: >>>> >>> >>>> >>>> Hi Congxian, >>>> >>>> Thanks for following up this issue. It is still unresolved and I >>>> am on >>>> >>>> vacation at the moment. Hopefully my collegues Niels and Vlad can >>>> spare >>>> >>>> some time to look into this. >>>> >>>> >>>> >>>> @Niels, @Vlad: do you guys also think that this issue might be >>>> Kafka >>>> >>>> related? We could also check kafka broker logs at the time of long >>>> >>>> checkpointing. >>>> >>>> >>>> >>>> Thanks, >>>> >>>> Bekir >>>> >>>> >>>> >>>> Verstuurd vanaf mijn iPhone >>>> >>>> >>>> >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>> het volgende geschreven: >>>> >>>> >>>> >>>> Hi Bekir >>>> >>>> >>>> >>>> Is there any progress about this problem? >>>> >>>> >>>> >>>> Best, >>>> >>>> Congxian >>>> >>>> >>>> >>>> >>>> >>>> Congxian Qiu <[hidden email]> 于2019年8月8日周四 下午11:17写道: >>>> >>>> >>>> >>>>> hi Bekir >>>> >>>>> Thanks for the information. >>>> >>>>> >>>> >>>>> - Source's checkpoint was triggered by RPC calls, so it has the >>>> >>>>> "Trigger checkpoint xxx" log, >>>> >>>>> - other task's checkpoint was triggered after received all the >>>> barrier >>>> >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( >>>> >>>>> >>>> >>>>> Your diagnose makes sense to me, we need to check the Kafka log. >>>> >>>>> I also find out that we always have a log like >>>> >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator >>>> Marking >>>> >>>>> the coordinator 172.19.200.73:9092 (id: 2147483646 rack: null) >>>> dead >>>> >>>>> for group userprofileaggregator >>>> >>>>> 2019-08-06 13:58:49,872 DEBUG >>>> >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - >>>> Notifica", >>>> >>>>> >>>> >>>>> I checked the doc of kafka[1], only find that the default of ` >>>> >>>>> transaction.max.timeout.ms` is 15 min >>>> >>>>> >>>> >>>>> Please let me know there you have any finds. thanks >>>> >>>>> >>>> >>>>> PS: maybe you can also checkpoint the log for task >>>> >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message >>>> late also. >>>> >>>>> >>>> >>>>> [1] https://kafka.apache.org/documentation/ >>>> >>>>> Best, >>>> >>>>> Congxian >>>> >>>>> >>>> >>>>> >>>> >>>>> Bekir Oguz <[hidden email]> 于2019年8月7日周三 下午6:48写道: >>>> >>>>> >>>> >>>>>> Hi Congxian, >>>> >>>>>> Thanks for checking the logs. What I see from the logs is: >>>> >>>>>> >>>> >>>>>> - For the tasks like "Source: >>>> >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” >>>> {17, 27, 31, >>>> >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also >>>> ‘Confirm >>>> >>>>>> checkpoint’ log lines, with 15 mins delay in between. >>>> >>>>>> - For the tasks like “KeyedProcess -> (Sink: >>>> >>>>>> profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We >>>> DO NOT have >>>> >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm >>>> checkpoint’ lines. >>>> >>>>>> >>>> >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator >>>> logs >>>> >>>>>> about lost connection to Kafka at the same time we have the >>>> checkpoints >>>> >>>>>> confirmed. This 15 minutes delay might be because of some >>>> timeout at the >>>> >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka >>>> coordinator >>>> >>>>>> dead, and then discovering kafka coordinator again. >>>> >>>>>> >>>> >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot >>>> confirm >>>> >>>>>> the checkpoints, cannot send the async offset commit request to >>>> Kafka. This >>>> >>>>>> could be the root cause of the problem. Please see the attached >>>> logs >>>> >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a >>>> 15 minutes >>>> >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 >>>> and 9:52) >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> I will enable Kafka DEBUG logging to see more and let you know >>>> about >>>> >>>>>> the findings. >>>> >>>>>> >>>> >>>>>> Thanks a lot for your support, >>>> >>>>>> Bekir Oguz >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>>>> het volgende geschreven: >>>> >>>>>> >>>> >>>>>> Hi >>>> >>>>>> >>>> >>>>>> Received all the files, as a first glance, the program uses at >>>> least >>>> >>>>>> once checkpoint mode, from the tm log, maybe we need to check >>>> checkpoint of >>>> >>>>>> this operator "Invoking async call Checkpoint Confirmation for >>>> KeyedProcess >>>> >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task >>>> KeyedProcess -> >>>> >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", >>>> >>>>>> >>>> >>>>>> Seems it took too long to complete the checkpoint (maybe >>>> something >>>> >>>>>> about itself, or maybe something of Kafka). I'll go through the >>>> logs >>>> >>>>>> carefully today or tomorrow again. >>>> >>>>>> >>>> >>>>>> Best, >>>> >>>>>> Congxian >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> Bekir Oguz <[hidden email]> 于2019年8月6日周二 下午10:38写道: >>>> >>>>>> >>>> >>>>>>> Ok, I am removing apache dev group from CC. >>>> >>>>>>> Only sending to you and my colleagues. >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>>> Thanks, >>>> >>>>>>> Bekir >>>> >>>>>>> >>>> >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz < >>>> [hidden email]> >>>> >>>>>>> het volgende geschreven: >>>> >>>>>>> >>>> >>>>>>> Hi Congxian, >>>> >>>>>>> Previous email didn’t work out due to size limits. >>>> >>>>>>> I am sending you only job manager log zipped, and will send >>>> other >>>> >>>>>>> info in separate email. >>>> >>>>>>> <jobmanager_sb77v.log.zip> >>>> >>>>>>> Regards, >>>> >>>>>>> Bekir >>>> >>>>>>> >>>> >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>>>>> het volgende geschreven: >>>> >>>>>>> >>>> >>>>>>> Hi Bekir >>>> >>>>>>> >>>> >>>>>>> Cloud you please also share the below information: >>>> >>>>>>> - jobmanager.log >>>> >>>>>>> - taskmanager.log(with debug info enabled) for the problematic >>>> >>>>>>> subtask. >>>> >>>>>>> - the DAG of your program (if can provide the skeleton program >>>> is >>>> >>>>>>> better -- can send to me privately) >>>> >>>>>>> >>>> >>>>>>> For the subIndex, maybe we can use the deploy log message in >>>> >>>>>>> jobmanager log to identify which subtask we want. For example >>>> in JM log, >>>> >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO >>>> >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - >>>> Deploying Source: >>>> >>>>>>> Custom Source (2/2) (attempt #0) to >>>> >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee >>>> >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was >>>> deplyed to " >>>> >>>>>>> aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still more >>>> than >>>> >>>>>>> one subtasks in one contain :( >>>> >>>>>>> >>>> >>>>>>> Best, >>>> >>>>>>> Congxian >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>>> Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道: >>>> >>>>>>> >>>> >>>>>>>> Forgot to add the checkpoint details after it was complete. >>>> This is >>>> >>>>>>>> for that long running checkpoint with id 95632. >>>> >>>>>>>> >>>> >>>>>>>> <PastedGraphic-5.png> >>>> >>>>>>>> >>>> >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz < >>>> [hidden email]> >>>> >>>>>>>> het volgende geschreven: >>>> >>>>>>>> >>>> >>>>>>>> Hi Congxian, >>>> >>>>>>>> I was able to fetch the logs of the task manager (attached) >>>> and the >>>> >>>>>>>> screenshots of the latest long checkpoint. I will get the logs >>>> of the job >>>> >>>>>>>> manager for the next long running checkpoint. And also I will >>>> try to get a >>>> >>>>>>>> jstack during the long running checkpoint. >>>> >>>>>>>> >>>> >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask >>>> numbers, >>>> >>>>>>>> and at the Details tab of the checkpoint, we have the subtask >>>> numbers but >>>> >>>>>>>> not the task manager hosts, it is difficult to match those. >>>> We’re assuming >>>> >>>>>>>> they have the same order, so seeing that 3rd subtask is >>>> failing, I am >>>> >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the >>>> task manager >>>> >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a >>>> great feature if >>>> >>>>>>>> you guys also include the subtask-id’s to the Subtasks view.*** >>>> >>>>>>>> >>>> >>>>>>>> Note: timestamps in the task manager log are in UTC and I am >>>> at the >>>> >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot >>>> matches the time >>>> >>>>>>>> 7:30 in the log. >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Kind regards, >>>> >>>>>>>> Bekir >>>> >>>>>>>> >>>> >>>>>>>> <task_manager.log> >>>> >>>>>>>> >>>> >>>>>>>> <PastedGraphic-4.png> >>>> >>>>>>>> <PastedGraphic-3.png> >>>> >>>>>>>> <PastedGraphic-2.png> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>>>>>> het volgende geschreven: >>>> >>>>>>>> >>>> >>>>>>>> Hi Bekir >>>> >>>>>>>> I’ll first summary the problem here(please correct me if I’m >>>> wrong) >>>> >>>>>>>> 1. The same program runs on 1.6 never encounter such problems >>>> >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other >>>> normal >>>> >>>>>>>> checkpoints complete less than 1 min >>>> >>>>>>>> 3. Some bad checkpoint will have a large sync time, async time >>>> >>>>>>>> seems ok >>>> >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger than >>>> >>>>>>>> (sync_time + async_time) >>>> >>>>>>>> First, answer the last question, the e2e duration is ack_time - >>>> >>>>>>>> trigger_time, so it always bigger than (sync_time + >>>> async_time), but we >>>> >>>>>>>> have a big gap here, this may be problematic. >>>> >>>>>>>> According to all the information, maybe the problem is some >>>> task >>>> >>>>>>>> start to do checkpoint too late and the sync checkpoint part >>>> took some time >>>> >>>>>>>> too long, Could you please share some more information such >>>> below: >>>> >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A >>>> here) >>>> >>>>>>>> - The detailed information of checkpoint A(includes all the >>>> >>>>>>>> problematic subtasks) >>>> >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic >>>> task >>>> >>>>>>>> and a health task >>>> >>>>>>>> - Share the screenshot of subtasks for the problematic >>>> >>>>>>>> task(includes the `Bytes received`, `Records received`, `Bytes >>>> sent`, >>>> >>>>>>>> `Records sent` column), here wants to compare the problematic >>>> parallelism >>>> >>>>>>>> and good parallelism’s information, please also share the >>>> information is >>>> >>>>>>>> there has a data skew among the parallelisms, >>>> >>>>>>>> - could you please share some jstacks of the problematic >>>> >>>>>>>> parallelism — here wants to check whether the task is too busy >>>> to handle >>>> >>>>>>>> the barrier. (flame graph or other things is always welcome >>>> here) >>>> >>>>>>>> >>>> >>>>>>>> Best, >>>> >>>>>>>> Congxian >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道: >>>> >>>>>>>> >>>> >>>>>>>>> Hi Bekir >>>> >>>>>>>>> >>>> >>>>>>>>> I'll first comb through all the information here, and try to >>>> find >>>> >>>>>>>>> out the reason with you, maybe need you to share some more >>>> information :) >>>> >>>>>>>>> >>>> >>>>>>>>> Best, >>>> >>>>>>>>> Congxian >>>> >>>>>>>>> >>>> >>>>>>>>> >>>> >>>>>>>>> Bekir Oguz <[hidden email]> 于2019年8月1日周四 下午5:00写道: >>>> >>>>>>>>> >>>> >>>>>>>>>> Hi Fabian, >>>> >>>>>>>>>> Thanks for sharing this with us, but we’re already on version >>>> >>>>>>>>>> 1.8.1. >>>> >>>>>>>>>> >>>> >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 >>>> >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you >>>> maybe give us some >>>> >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 >>>> minutes defined >>>> >>>>>>>>>> somewhere in Flink? I couldn’t find one. >>>> >>>>>>>>>> >>>> >>>>>>>>>> In our pipeline, most of the checkpoints complete in less >>>> than a >>>> >>>>>>>>>> minute and some of them completed in 15 minutes+(less than a >>>> minute). >>>> >>>>>>>>>> There’s definitely something which adds 15 minutes. This is >>>> >>>>>>>>>> happening in one or more subtasks during checkpointing. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Please see the screenshot below: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Regards, >>>> >>>>>>>>>> Bekir >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske < >>>> [hidden email]> >>>> >>>>>>>>>> het volgende geschreven: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi Bekir, >>>> >>>>>>>>>> >>>> >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 >>>> [1]. >>>> >>>>>>>>>> These seem to be resolved with Flink 1.8.1. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hope this helps, >>>> >>>>>>>>>> Fabian >>>> >>>>>>>>>> >>>> >>>>>>>>>> [1] >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E >>>> >>>>>>>>>> >>>> >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < >>>> >>>>>>>>>> [hidden email]>: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi Bekir >>>> >>>>>>>>>> >>>> >>>>>>>>>> First of all, I think there is something wrong. the state >>>> size >>>> >>>>>>>>>> is almost >>>> >>>>>>>>>> the same, but the duration is different so much. >>>> >>>>>>>>>> >>>> >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, >>>> then >>>> >>>>>>>>>> copy the >>>> >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the >>>> sst >>>> >>>>>>>>>> files >>>> >>>>>>>>>> already on remote will not upload), then complete >>>> checkpoint. Can >>>> >>>>>>>>>> you check >>>> >>>>>>>>>> the network bandwidth usage during checkpoint? >>>> >>>>>>>>>> >>>> >>>>>>>>>> Best, >>>> >>>>>>>>>> Congxian >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Bekir Oguz <[hidden email]> 于2019年7月16日周二 >>>> 下午10:45写道: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi all, >>>> >>>>>>>>>> We have a flink job with user state, checkpointing to >>>> >>>>>>>>>> RocksDBBackend >>>> >>>>>>>>>> which is externally stored in AWS S3. >>>> >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see >>>> >>>>>>>>>> occasionally >>>> >>>>>>>>>> that some slots do to acknowledge the checkpoints quick >>>> enough. >>>> >>>>>>>>>> As an >>>> >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except >>>> only >>>> >>>>>>>>>> one slot >>>> >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to each >>>> >>>>>>>>>> other, like >>>> >>>>>>>>>> 200-400 MB. >>>> >>>>>>>>>> >>>> >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We >>>> have >>>> >>>>>>>>>> 5 min >>>> >>>>>>>>>> checkpoint interval and this happens sometimes once in an >>>> hour >>>> >>>>>>>>>> sometimes >>>> >>>>>>>>>> more but not in all the checkpoint requests. Please see the >>>> >>>>>>>>>> screenshot >>>> >>>>>>>>>> below. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Also another point: For the faulty slots, the duration is >>>> >>>>>>>>>> consistently 15 >>>> >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 >>>> mins >>>> >>>>>>>>>> response >>>> >>>>>>>>>> time comes from. And each time it is a different task >>>> manager, >>>> >>>>>>>>>> not always >>>> >>>>>>>>>> the same one. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Do you guys aware of any other users having similar issues >>>> with >>>> >>>>>>>>>> the new >>>> >>>>>>>>>> version and also a suggested bug fix or solution? >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Thanks in advance, >>>> >>>>>>>>>> Bekir Oguz >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>> >>>> >> >>>> >> -- >>>> >> -- Bekir Oguz >>>> >> >>>> > >>>> >>> >> >> -- >> -- Bekir Oguz >> > |
|
|
Hi Bekir
From what I could see, there should be two main factors influencing your time of sync execution checkpoint within that task. 1. Snapshot timers in heap to S3 [1] (network IO) 2. Creating local RocksDB checkpoint on disk [2] (disk IO) For the first part, unfortunately, there is no log or metrics could detect how long it takes. For the second part, you could login the machine where running that task, and find logs of RocksDB (default DB folder is {io.tmp.dirs}/flink-io-xxx/job-xxx/db and the log file name is LOG). You could check the interval of logs between "Started the snapshot process -- creating snapshot in directory" and "Snapshot DONE" to know how long RocksDB takes to create checkpoint on local disk. If we configure "state.backend.rocksdb.timer-service.factory" to "ROCKSDB", we could avoid the 1st part of time and this might be a solution to your problem. But to be honest, the implementation of timer snapshot code almost stay the same for Flink-1.6 and Flink-1.8 and should not be a regression. [1] https://github.com/apache/flink/blob/ba1cd43b6ed42070fd9013159a5b65adb18b3975/flink-streaming-java/src/main/java/org/apache/flink/streaming/api/operators/AbstractStreamOperator.java#L453 [2] https://github.com/apache/flink/blob/ba1cd43b6ed42070fd9013159a5b65adb18b3975/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/snapshot/RocksIncrementalSnapshotStrategy.java#L249 Best Yun Tang ________________________________ From: Congxian Qiu <[hidden email]> Sent: Thursday, September 5, 2019 10:38 To: Bekir Oguz <[hidden email]> Cc: Stephan Ewen <[hidden email]>; dev <[hidden email]>; Niels Alebregtse <[hidden email]>; Vladislav Bakayev <[hidden email]> Subject: Re: instable checkpointing after migration to flink 1.8 Another information from our private emails there ALWAYS have Kafka AbstractCoordinator logs about lost connection to Kafka at the same time we have the checkpoints confirmed. Bekir checked the Kafka broker log, but did not find any interesting things there. Best, Congxian Congxian Qiu <[hidden email]> 于2019年9月5日周四 上午10:26写道: > Hi Bekir, > > If it is the storage place for timers, for RocksDBStateBackend, timers can > be stored in Heap or RocksDB[1][2] > [1] > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/large_state_tuning.html#tuning-rocksdb > [2] > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/state_backends.html#rocksdb-state-backend-config-options > > Best, > Congxian > > > Bekir Oguz <[hidden email]> 于2019年9月4日周三 下午11:38写道: > >> Hi Stephan, >> sorry for late response. >> We indeed use timers inside a KeyedProcessFunction but the triggers of >> the timers are kinda evenly distributed, so not causing a firing storm. >> We have a custom ttl logic which is used by the deletion timer to decide >> whether delete a record from inmemory state or not. >> Can you maybe give some links to those changes in the RocksDB? >> >> Thanks in advance, >> Bekir Oguz >> >> On Fri, 30 Aug 2019 at 14:56, Stephan Ewen <[hidden email]> wrote: >> >>> Hi all! >>> >>> A thought would be that this has something to do with timers. Does the >>> task with that behavior use timers (windows, or process function)? >>> >>> If that is the case, some theories to check: >>> - Could it be a timer firing storm coinciding with a checkpoint? >>> Currently, that storm synchronously fires, checkpoints cannot preempt that, >>> which should change in 1.10 with the new mailbox model. >>> - Could the timer-async checkpointing changes have something to do >>> with that? Does some of the usually small "preparation work" (happening >>> synchronously) lead to an unwanted effect? >>> - Are you using TTL for state in that operator? >>> - There were some changes made to support timers in RocksDB recently. >>> Could that have something to do with it? >>> >>> Best, >>> Stephan >>> >>> >>> On Fri, Aug 30, 2019 at 2:45 PM Congxian Qiu <[hidden email]> >>> wrote: >>> >>>> CC flink dev mail list >>>> Update for those who may be interested in this issue, we'are still >>>> diagnosing this problem currently. >>>> >>>> Best, >>>> Congxian >>>> >>>> >>>> Congxian Qiu <[hidden email]> 于2019年8月29日周四 下午8:58写道: >>>> >>>> > Hi Bekir >>>> > >>>> > Currently, from what we have diagnosed, there is some task complete >>>> its >>>> > checkpoint too late (maybe 15 mins), but we checked the kafka broker >>>> log >>>> > and did not find any interesting things there. could we run another >>>> job, >>>> > that did not commit offset to kafka, this wants to check if it is the >>>> > "commit offset to kafka" step consumes too much time. >>>> > >>>> > Best, >>>> > Congxian >>>> > >>>> > >>>> > Bekir Oguz <[hidden email]> 于2019年8月28日周三 下午4:19写道: >>>> > >>>> >> Hi Congxian, >>>> >> sorry for the late reply, but no progress on this issue yet. I >>>> checked >>>> >> also the kafka broker logs, found nothing interesting there. >>>> >> And we still have 15 min duration checkpoints quite often. Any more >>>> ideas >>>> >> on where to look at? >>>> >> >>>> >> Regards, >>>> >> Bekir >>>> >> >>>> >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email]> >>>> >> wrote: >>>> >> >>>> >>> Hi Bekir >>>> >>> >>>> >>> Do you come back to work now, does there any more findings of this >>>> >>> problem? >>>> >>> >>>> >>> Best, >>>> >>> Congxian >>>> >>> >>>> >>> >>>> >>> Bekir Oguz <[hidden email]> 于2019年8月13日周二 下午4:39写道: >>>> >>> >>>> >>>> Hi Congxian, >>>> >>>> Thanks for following up this issue. It is still unresolved and I >>>> am on >>>> >>>> vacation at the moment. Hopefully my collegues Niels and Vlad can >>>> spare >>>> >>>> some time to look into this. >>>> >>>> >>>> >>>> @Niels, @Vlad: do you guys also think that this issue might be >>>> Kafka >>>> >>>> related? We could also check kafka broker logs at the time of long >>>> >>>> checkpointing. >>>> >>>> >>>> >>>> Thanks, >>>> >>>> Bekir >>>> >>>> >>>> >>>> Verstuurd vanaf mijn iPhone >>>> >>>> >>>> >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>> het volgende geschreven: >>>> >>>> >>>> >>>> Hi Bekir >>>> >>>> >>>> >>>> Is there any progress about this problem? >>>> >>>> >>>> >>>> Best, >>>> >>>> Congxian >>>> >>>> >>>> >>>> >>>> >>>> Congxian Qiu <[hidden email]> 于2019年8月8日周四 下午11:17写道: >>>> >>>> >>>> >>>>> hi Bekir >>>> >>>>> Thanks for the information. >>>> >>>>> >>>> >>>>> - Source's checkpoint was triggered by RPC calls, so it has the >>>> >>>>> "Trigger checkpoint xxx" log, >>>> >>>>> - other task's checkpoint was triggered after received all the >>>> barrier >>>> >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( >>>> >>>>> >>>> >>>>> Your diagnose makes sense to me, we need to check the Kafka log. >>>> >>>>> I also find out that we always have a log like >>>> >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator >>>> Marking >>>> >>>>> the coordinator 172.19.200.73:9092 (id: 2147483646 rack: null) >>>> dead >>>> >>>>> for group userprofileaggregator >>>> >>>>> 2019-08-06 13:58:49,872 DEBUG >>>> >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - >>>> Notifica", >>>> >>>>> >>>> >>>>> I checked the doc of kafka[1], only find that the default of ` >>>> >>>>> transaction.max.timeout.ms` is 15 min >>>> >>>>> >>>> >>>>> Please let me know there you have any finds. thanks >>>> >>>>> >>>> >>>>> PS: maybe you can also checkpoint the log for task >>>> >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message >>>> late also. >>>> >>>>> >>>> >>>>> [1] https://kafka.apache.org/documentation/ >>>> >>>>> Best, >>>> >>>>> Congxian >>>> >>>>> >>>> >>>>> >>>> >>>>> Bekir Oguz <[hidden email]> 于2019年8月7日周三 下午6:48写道: >>>> >>>>> >>>> >>>>>> Hi Congxian, >>>> >>>>>> Thanks for checking the logs. What I see from the logs is: >>>> >>>>>> >>>> >>>>>> - For the tasks like "Source: >>>> >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” >>>> {17, 27, 31, >>>> >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also >>>> ‘Confirm >>>> >>>>>> checkpoint’ log lines, with 15 mins delay in between. >>>> >>>>>> - For the tasks like “KeyedProcess -> (Sink: >>>> >>>>>> profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We >>>> DO NOT have >>>> >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm >>>> checkpoint’ lines. >>>> >>>>>> >>>> >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator >>>> logs >>>> >>>>>> about lost connection to Kafka at the same time we have the >>>> checkpoints >>>> >>>>>> confirmed. This 15 minutes delay might be because of some >>>> timeout at the >>>> >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka >>>> coordinator >>>> >>>>>> dead, and then discovering kafka coordinator again. >>>> >>>>>> >>>> >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot >>>> confirm >>>> >>>>>> the checkpoints, cannot send the async offset commit request to >>>> Kafka. This >>>> >>>>>> could be the root cause of the problem. Please see the attached >>>> logs >>>> >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a >>>> 15 minutes >>>> >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 >>>> and 9:52) >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> I will enable Kafka DEBUG logging to see more and let you know >>>> about >>>> >>>>>> the findings. >>>> >>>>>> >>>> >>>>>> Thanks a lot for your support, >>>> >>>>>> Bekir Oguz >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>>>> het volgende geschreven: >>>> >>>>>> >>>> >>>>>> Hi >>>> >>>>>> >>>> >>>>>> Received all the files, as a first glance, the program uses at >>>> least >>>> >>>>>> once checkpoint mode, from the tm log, maybe we need to check >>>> checkpoint of >>>> >>>>>> this operator "Invoking async call Checkpoint Confirmation for >>>> KeyedProcess >>>> >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task >>>> KeyedProcess -> >>>> >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", >>>> >>>>>> >>>> >>>>>> Seems it took too long to complete the checkpoint (maybe >>>> something >>>> >>>>>> about itself, or maybe something of Kafka). I'll go through the >>>> logs >>>> >>>>>> carefully today or tomorrow again. >>>> >>>>>> >>>> >>>>>> Best, >>>> >>>>>> Congxian >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> Bekir Oguz <[hidden email]> 于2019年8月6日周二 下午10:38写道: >>>> >>>>>> >>>> >>>>>>> Ok, I am removing apache dev group from CC. >>>> >>>>>>> Only sending to you and my colleagues. >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>>> Thanks, >>>> >>>>>>> Bekir >>>> >>>>>>> >>>> >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz < >>>> [hidden email]> >>>> >>>>>>> het volgende geschreven: >>>> >>>>>>> >>>> >>>>>>> Hi Congxian, >>>> >>>>>>> Previous email didn’t work out due to size limits. >>>> >>>>>>> I am sending you only job manager log zipped, and will send >>>> other >>>> >>>>>>> info in separate email. >>>> >>>>>>> <jobmanager_sb77v.log.zip> >>>> >>>>>>> Regards, >>>> >>>>>>> Bekir >>>> >>>>>>> >>>> >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>>>>> het volgende geschreven: >>>> >>>>>>> >>>> >>>>>>> Hi Bekir >>>> >>>>>>> >>>> >>>>>>> Cloud you please also share the below information: >>>> >>>>>>> - jobmanager.log >>>> >>>>>>> - taskmanager.log(with debug info enabled) for the problematic >>>> >>>>>>> subtask. >>>> >>>>>>> - the DAG of your program (if can provide the skeleton program >>>> is >>>> >>>>>>> better -- can send to me privately) >>>> >>>>>>> >>>> >>>>>>> For the subIndex, maybe we can use the deploy log message in >>>> >>>>>>> jobmanager log to identify which subtask we want. For example >>>> in JM log, >>>> >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO >>>> >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - >>>> Deploying Source: >>>> >>>>>>> Custom Source (2/2) (attempt #0) to >>>> >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee >>>> >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was >>>> deplyed to " >>>> >>>>>>> aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still more >>>> than >>>> >>>>>>> one subtasks in one contain :( >>>> >>>>>>> >>>> >>>>>>> Best, >>>> >>>>>>> Congxian >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>>> Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道: >>>> >>>>>>> >>>> >>>>>>>> Forgot to add the checkpoint details after it was complete. >>>> This is >>>> >>>>>>>> for that long running checkpoint with id 95632. >>>> >>>>>>>> >>>> >>>>>>>> <PastedGraphic-5.png> >>>> >>>>>>>> >>>> >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz < >>>> [hidden email]> >>>> >>>>>>>> het volgende geschreven: >>>> >>>>>>>> >>>> >>>>>>>> Hi Congxian, >>>> >>>>>>>> I was able to fetch the logs of the task manager (attached) >>>> and the >>>> >>>>>>>> screenshots of the latest long checkpoint. I will get the logs >>>> of the job >>>> >>>>>>>> manager for the next long running checkpoint. And also I will >>>> try to get a >>>> >>>>>>>> jstack during the long running checkpoint. >>>> >>>>>>>> >>>> >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask >>>> numbers, >>>> >>>>>>>> and at the Details tab of the checkpoint, we have the subtask >>>> numbers but >>>> >>>>>>>> not the task manager hosts, it is difficult to match those. >>>> We’re assuming >>>> >>>>>>>> they have the same order, so seeing that 3rd subtask is >>>> failing, I am >>>> >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the >>>> task manager >>>> >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a >>>> great feature if >>>> >>>>>>>> you guys also include the subtask-id’s to the Subtasks view.*** >>>> >>>>>>>> >>>> >>>>>>>> Note: timestamps in the task manager log are in UTC and I am >>>> at the >>>> >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot >>>> matches the time >>>> >>>>>>>> 7:30 in the log. >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Kind regards, >>>> >>>>>>>> Bekir >>>> >>>>>>>> >>>> >>>>>>>> <task_manager.log> >>>> >>>>>>>> >>>> >>>>>>>> <PastedGraphic-4.png> >>>> >>>>>>>> <PastedGraphic-3.png> >>>> >>>>>>>> <PastedGraphic-2.png> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu < >>>> [hidden email]> >>>> >>>>>>>> het volgende geschreven: >>>> >>>>>>>> >>>> >>>>>>>> Hi Bekir >>>> >>>>>>>> I’ll first summary the problem here(please correct me if I’m >>>> wrong) >>>> >>>>>>>> 1. The same program runs on 1.6 never encounter such problems >>>> >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other >>>> normal >>>> >>>>>>>> checkpoints complete less than 1 min >>>> >>>>>>>> 3. Some bad checkpoint will have a large sync time, async time >>>> >>>>>>>> seems ok >>>> >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger than >>>> >>>>>>>> (sync_time + async_time) >>>> >>>>>>>> First, answer the last question, the e2e duration is ack_time - >>>> >>>>>>>> trigger_time, so it always bigger than (sync_time + >>>> async_time), but we >>>> >>>>>>>> have a big gap here, this may be problematic. >>>> >>>>>>>> According to all the information, maybe the problem is some >>>> task >>>> >>>>>>>> start to do checkpoint too late and the sync checkpoint part >>>> took some time >>>> >>>>>>>> too long, Could you please share some more information such >>>> below: >>>> >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A >>>> here) >>>> >>>>>>>> - The detailed information of checkpoint A(includes all the >>>> >>>>>>>> problematic subtasks) >>>> >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic >>>> task >>>> >>>>>>>> and a health task >>>> >>>>>>>> - Share the screenshot of subtasks for the problematic >>>> >>>>>>>> task(includes the `Bytes received`, `Records received`, `Bytes >>>> sent`, >>>> >>>>>>>> `Records sent` column), here wants to compare the problematic >>>> parallelism >>>> >>>>>>>> and good parallelism’s information, please also share the >>>> information is >>>> >>>>>>>> there has a data skew among the parallelisms, >>>> >>>>>>>> - could you please share some jstacks of the problematic >>>> >>>>>>>> parallelism ― here wants to check whether the task is too busy >>>> to handle >>>> >>>>>>>> the barrier. (flame graph or other things is always welcome >>>> here) >>>> >>>>>>>> >>>> >>>>>>>> Best, >>>> >>>>>>>> Congxian >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道: >>>> >>>>>>>> >>>> >>>>>>>>> Hi Bekir >>>> >>>>>>>>> >>>> >>>>>>>>> I'll first comb through all the information here, and try to >>>> find >>>> >>>>>>>>> out the reason with you, maybe need you to share some more >>>> information :) >>>> >>>>>>>>> >>>> >>>>>>>>> Best, >>>> >>>>>>>>> Congxian >>>> >>>>>>>>> >>>> >>>>>>>>> >>>> >>>>>>>>> Bekir Oguz <[hidden email]> 于2019年8月1日周四 下午5:00写道: >>>> >>>>>>>>> >>>> >>>>>>>>>> Hi Fabian, >>>> >>>>>>>>>> Thanks for sharing this with us, but we’re already on version >>>> >>>>>>>>>> 1.8.1. >>>> >>>>>>>>>> >>>> >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 >>>> >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you >>>> maybe give us some >>>> >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 >>>> minutes defined >>>> >>>>>>>>>> somewhere in Flink? I couldn’t find one. >>>> >>>>>>>>>> >>>> >>>>>>>>>> In our pipeline, most of the checkpoints complete in less >>>> than a >>>> >>>>>>>>>> minute and some of them completed in 15 minutes+(less than a >>>> minute). >>>> >>>>>>>>>> There’s definitely something which adds 15 minutes. This is >>>> >>>>>>>>>> happening in one or more subtasks during checkpointing. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Please see the screenshot below: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Regards, >>>> >>>>>>>>>> Bekir >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske < >>>> [hidden email]> >>>> >>>>>>>>>> het volgende geschreven: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi Bekir, >>>> >>>>>>>>>> >>>> >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 >>>> [1]. >>>> >>>>>>>>>> These seem to be resolved with Flink 1.8.1. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hope this helps, >>>> >>>>>>>>>> Fabian >>>> >>>>>>>>>> >>>> >>>>>>>>>> [1] >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E >>>> >>>>>>>>>> >>>> >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < >>>> >>>>>>>>>> [hidden email]>: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi Bekir >>>> >>>>>>>>>> >>>> >>>>>>>>>> First of all, I think there is something wrong. the state >>>> size >>>> >>>>>>>>>> is almost >>>> >>>>>>>>>> the same, but the duration is different so much. >>>> >>>>>>>>>> >>>> >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, >>>> then >>>> >>>>>>>>>> copy the >>>> >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the >>>> sst >>>> >>>>>>>>>> files >>>> >>>>>>>>>> already on remote will not upload), then complete >>>> checkpoint. Can >>>> >>>>>>>>>> you check >>>> >>>>>>>>>> the network bandwidth usage during checkpoint? >>>> >>>>>>>>>> >>>> >>>>>>>>>> Best, >>>> >>>>>>>>>> Congxian >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Bekir Oguz <[hidden email]> 于2019年7月16日周二 >>>> 下午10:45写道: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi all, >>>> >>>>>>>>>> We have a flink job with user state, checkpointing to >>>> >>>>>>>>>> RocksDBBackend >>>> >>>>>>>>>> which is externally stored in AWS S3. >>>> >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see >>>> >>>>>>>>>> occasionally >>>> >>>>>>>>>> that some slots do to acknowledge the checkpoints quick >>>> enough. >>>> >>>>>>>>>> As an >>>> >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except >>>> only >>>> >>>>>>>>>> one slot >>>> >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to each >>>> >>>>>>>>>> other, like >>>> >>>>>>>>>> 200-400 MB. >>>> >>>>>>>>>> >>>> >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We >>>> have >>>> >>>>>>>>>> 5 min >>>> >>>>>>>>>> checkpoint interval and this happens sometimes once in an >>>> hour >>>> >>>>>>>>>> sometimes >>>> >>>>>>>>>> more but not in all the checkpoint requests. Please see the >>>> >>>>>>>>>> screenshot >>>> >>>>>>>>>> below. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Also another point: For the faulty slots, the duration is >>>> >>>>>>>>>> consistently 15 >>>> >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 >>>> mins >>>> >>>>>>>>>> response >>>> >>>>>>>>>> time comes from. And each time it is a different task >>>> manager, >>>> >>>>>>>>>> not always >>>> >>>>>>>>>> the same one. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Do you guys aware of any other users having similar issues >>>> with >>>> >>>>>>>>>> the new >>>> >>>>>>>>>> version and also a suggested bug fix or solution? >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Thanks in advance, >>>> >>>>>>>>>> Bekir Oguz >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>> >>>> >> >>>> >> -- >>>> >> -- Bekir Oguz >>>> >> >>>> > >>>> >>> >> >> -- >> -- Bekir Oguz >> > |
Re: instable checkpointing after migration to flink 1.8
|
|
Hi Yun,
first of all, this reported problem looks like resolved for 2 days already, right after we changed the type and number of our nodes to give more heap to task managers and have more task-managers as well. Previously, our job was configured as parallelism 70, which was distributed to 14 task-managers (5 slots/tm) each having 9GB heap. After our config change, the job is now using parallelism 100, distributed to 20 task-managers (5 slots/tm) each having 18GB heap. This job has a keyed process function which manages ~400 million records in its state, and creating 1 timer per record scheduled to trigger in 6 months to check if the record is eligible to be wiped out from state or not. So we have 400M records + 400M timers. For user state, we use RocksDB backend with incremental checkpointing enabled and using s3 as an external checkpoint location. RocksDB backend is configured with predefined FLASH_SSD_OPTIMIZED values. Before our config change, flink was managing 400M/14=28,5M records + 28,5M timers in each task-manager with 9GB heap. And after the config change, this is 400M/20=20M records + 20M timers in each task-manager with 18GB heap. So, we have less state to manage per task manager, and have more heap. Apparently this fixes(!) the problem of long checkpointing durations (15 minutes) happening occasionally. Coming back to your points: 1. Snapshot timers are indeed using HEAP which is the default. We can set it to ROCKSDB to see if that change has an impact on the end-to-end checkpoint duration. Do you think this change will also reduce the heap usage? 2. I have collected and shared those logs under /tmp directory earlier and noticed that snapshotting happens very fast, finishing in a second. But what I noticed was, compaction kicking in during the snapshotting phase of a long (15 minutes) checkpoint. But still, the time spent for snapshotting was 1 second. I guess compaction has no impact there. And still do not know why it took 15 mins to acknowledge for one task slot. I have another question regarding this problem and our use of timers. Is this a good practice to use timers like we do? Does the flink timer service support having this many timers? One timer per record, which is 400 million for us. Looks like our problem is solved for the time being, but may appear again since we still do not know the root cause. About the use of timers: Could you please share your opinion on our timer setup and maybe support us on my question on switching timers to use rocksdb instead of heap? Thanks a lot, Bekir Oguz On Thu, 5 Sep 2019 at 19:55, Yun Tang <[hidden email]> wrote: > Hi Bekir > > From what I could see, there should be two main factors influencing your > time of sync execution checkpoint within that task. > > 1. Snapshot timers in heap to S3 [1] (network IO) > 2. Creating local RocksDB checkpoint on disk [2] (disk IO) > > For the first part, unfortunately, there is no log or metrics could detect > how long it takes. > For the second part, you could login the machine where running that task, > and find logs of RocksDB (default DB folder is > {io.tmp.dirs}/flink-io-xxx/job-xxx/db and the log file name is *LOG*). > You could check the interval of logs between "Started the snapshot process > -- creating snapshot in directory" and "Snapshot DONE" to know how long > RocksDB takes to create checkpoint on local disk. > > If we configure "state.backend.rocksdb.timer-service.factory" to > "ROCKSDB", we could avoid the 1st part of time and this might be a solution > to your problem. But to be honest, the implementation of timer snapshot > code almost stay the same for Flink-1.6 and Flink-1.8 and should not be a > regression. > > [1] > https://github.com/apache/flink/blob/ba1cd43b6ed42070fd9013159a5b65adb18b3975/flink-streaming-java/src/main/java/org/apache/flink/streaming/api/operators/AbstractStreamOperator.java#L453 > [2] > https://github.com/apache/flink/blob/ba1cd43b6ed42070fd9013159a5b65adb18b3975/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/snapshot/RocksIncrementalSnapshotStrategy.java#L249 > > Best > Yun Tang > ------------------------------ > *From:* Congxian Qiu <[hidden email]> > *Sent:* Thursday, September 5, 2019 10:38 > *To:* Bekir Oguz <[hidden email]> > *Cc:* Stephan Ewen <[hidden email]>; dev <[hidden email]>; Niels > Alebregtse <[hidden email]>; Vladislav Bakayev < > [hidden email]> > *Subject:* Re: instable checkpointing after migration to flink 1.8 > > Another information from our private emails > > there ALWAYS have Kafka AbstractCoordinator logs about lost connection to > Kafka at the same time we have the checkpoints confirmed. Bekir checked the > Kafka broker log, but did not find any interesting things there. > > Best, > Congxian > > > Congxian Qiu <[hidden email]> 于2019年9月5日周四 上午10:26写道: > > > Hi Bekir, > > > > If it is the storage place for timers, for RocksDBStateBackend, timers > can > > be stored in Heap or RocksDB[1][2] > > [1] > > > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/large_state_tuning.html#tuning-rocksdb > > [2] > > > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/state_backends.html#rocksdb-state-backend-config-options > > > > Best, > > Congxian > > > > > > Bekir Oguz <[hidden email]> 于2019年9月4日周三 下午11:38写道: > > > >> Hi Stephan, > >> sorry for late response. > >> We indeed use timers inside a KeyedProcessFunction but the triggers of > >> the timers are kinda evenly distributed, so not causing a firing storm. > >> We have a custom ttl logic which is used by the deletion timer to decide > >> whether delete a record from inmemory state or not. > >> Can you maybe give some links to those changes in the RocksDB? > >> > >> Thanks in advance, > >> Bekir Oguz > >> > >> On Fri, 30 Aug 2019 at 14:56, Stephan Ewen <[hidden email]> wrote: > >> > >>> Hi all! > >>> > >>> A thought would be that this has something to do with timers. Does the > >>> task with that behavior use timers (windows, or process function)? > >>> > >>> If that is the case, some theories to check: > >>> - Could it be a timer firing storm coinciding with a checkpoint? > >>> Currently, that storm synchronously fires, checkpoints cannot preempt > that, > >>> which should change in 1.10 with the new mailbox model. > >>> - Could the timer-async checkpointing changes have something to do > >>> with that? Does some of the usually small "preparation work" (happening > >>> synchronously) lead to an unwanted effect? > >>> - Are you using TTL for state in that operator? > >>> - There were some changes made to support timers in RocksDB recently. > >>> Could that have something to do with it? > >>> > >>> Best, > >>> Stephan > >>> > >>> > >>> On Fri, Aug 30, 2019 at 2:45 PM Congxian Qiu <[hidden email]> > >>> wrote: > >>> > >>>> CC flink dev mail list > >>>> Update for those who may be interested in this issue, we'are still > >>>> diagnosing this problem currently. > >>>> > >>>> Best, > >>>> Congxian > >>>> > >>>> > >>>> Congxian Qiu <[hidden email]> 于2019年8月29日周四 下午8:58写道: > >>>> > >>>> > Hi Bekir > >>>> > > >>>> > Currently, from what we have diagnosed, there is some task complete > >>>> its > >>>> > checkpoint too late (maybe 15 mins), but we checked the kafka broker > >>>> log > >>>> > and did not find any interesting things there. could we run another > >>>> job, > >>>> > that did not commit offset to kafka, this wants to check if it is > the > >>>> > "commit offset to kafka" step consumes too much time. > >>>> > > >>>> > Best, > >>>> > Congxian > >>>> > > >>>> > > >>>> > Bekir Oguz <[hidden email]> 于2019年8月28日周三 下午4:19写道: > >>>> > > >>>> >> Hi Congxian, > >>>> >> sorry for the late reply, but no progress on this issue yet. I > >>>> checked > >>>> >> also the kafka broker logs, found nothing interesting there. > >>>> >> And we still have 15 min duration checkpoints quite often. Any more > >>>> ideas > >>>> >> on where to look at? > >>>> >> > >>>> >> Regards, > >>>> >> Bekir > >>>> >> > >>>> >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email] > > > >>>> >> wrote: > >>>> >> > >>>> >>> Hi Bekir > >>>> >>> > >>>> >>> Do you come back to work now, does there any more findings of this > >>>> >>> problem? > >>>> >>> > >>>> >>> Best, > >>>> >>> Congxian > >>>> >>> > >>>> >>> > >>>> >>> Bekir Oguz <[hidden email]> 于2019年8月13日周二 下午4:39写道: > >>>> >>> > >>>> >>>> Hi Congxian, > >>>> >>>> Thanks for following up this issue. It is still unresolved and I > >>>> am on > >>>> >>>> vacation at the moment. Hopefully my collegues Niels and Vlad > can > >>>> spare > >>>> >>>> some time to look into this. > >>>> >>>> > >>>> >>>> @Niels, @Vlad: do you guys also think that this issue might be > >>>> Kafka > >>>> >>>> related? We could also check kafka broker logs at the time of > long > >>>> >>>> checkpointing. > >>>> >>>> > >>>> >>>> Thanks, > >>>> >>>> Bekir > >>>> >>>> > >>>> >>>> Verstuurd vanaf mijn iPhone > >>>> >>>> > >>>> >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu < > >>>> [hidden email]> > >>>> >>>> het volgende geschreven: > >>>> >>>> > >>>> >>>> Hi Bekir > >>>> >>>> > >>>> >>>> Is there any progress about this problem? > >>>> >>>> > >>>> >>>> Best, > >>>> >>>> Congxian > >>>> >>>> > >>>> >>>> > >>>> >>>> Congxian Qiu <[hidden email]> 于2019年8月8日周四 下午11:17写道: > >>>> >>>> > >>>> >>>>> hi Bekir > >>>> >>>>> Thanks for the information. > >>>> >>>>> > >>>> >>>>> - Source's checkpoint was triggered by RPC calls, so it has the > >>>> >>>>> "Trigger checkpoint xxx" log, > >>>> >>>>> - other task's checkpoint was triggered after received all the > >>>> barrier > >>>> >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( > >>>> >>>>> > >>>> >>>>> Your diagnose makes sense to me, we need to check the Kafka log. > >>>> >>>>> I also find out that we always have a log like > >>>> >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator > >>>> Marking > >>>> >>>>> the coordinator 172.19.200.73:9092 (id: 2147483646 rack: null) > >>>> dead > >>>> >>>>> for group userprofileaggregator > >>>> >>>>> 2019-08-06 13:58:49,872 DEBUG > >>>> >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - > >>>> Notifica", > >>>> >>>>> > >>>> >>>>> I checked the doc of kafka[1], only find that the default of ` > >>>> >>>>> transaction.max.timeout.ms` is 15 min > >>>> >>>>> > >>>> >>>>> Please let me know there you have any finds. thanks > >>>> >>>>> > >>>> >>>>> PS: maybe you can also checkpoint the log for task > >>>> >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message > >>>> late also. > >>>> >>>>> > >>>> >>>>> [1] https://kafka.apache.org/documentation/ > >>>> >>>>> Best, > >>>> >>>>> Congxian > >>>> >>>>> > >>>> >>>>> > >>>> >>>>> Bekir Oguz <[hidden email]> 于2019年8月7日周三 下午6:48写道: > >>>> >>>>> > >>>> >>>>>> Hi Congxian, > >>>> >>>>>> Thanks for checking the logs. What I see from the logs is: > >>>> >>>>>> > >>>> >>>>>> - For the tasks like "Source: > >>>> >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” > >>>> {17, 27, 31, > >>>> >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also > >>>> ‘Confirm > >>>> >>>>>> checkpoint’ log lines, with 15 mins delay in between. > >>>> >>>>>> - For the tasks like “KeyedProcess -> (Sink: > >>>> >>>>>> profileservice-userprofiles_kafka_sink, Sink: > >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: > >>>> >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We > >>>> DO NOT have > >>>> >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm > >>>> checkpoint’ lines. > >>>> >>>>>> > >>>> >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator > >>>> logs > >>>> >>>>>> about lost connection to Kafka at the same time we have the > >>>> checkpoints > >>>> >>>>>> confirmed. This 15 minutes delay might be because of some > >>>> timeout at the > >>>> >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka > >>>> coordinator > >>>> >>>>>> dead, and then discovering kafka coordinator again. > >>>> >>>>>> > >>>> >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot > >>>> confirm > >>>> >>>>>> the checkpoints, cannot send the async offset commit request to > >>>> Kafka. This > >>>> >>>>>> could be the root cause of the problem. Please see the attached > >>>> logs > >>>> >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a > >>>> 15 minutes > >>>> >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 > >>>> and 9:52) > >>>> >>>>>> > >>>> >>>>>> > >>>> >>>>>> I will enable Kafka DEBUG logging to see more and let you know > >>>> about > >>>> >>>>>> the findings. > >>>> >>>>>> > >>>> >>>>>> Thanks a lot for your support, > >>>> >>>>>> Bekir Oguz > >>>> >>>>>> > >>>> >>>>>> > >>>> >>>>>> > >>>> >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu < > >>>> [hidden email]> > >>>> >>>>>> het volgende geschreven: > >>>> >>>>>> > >>>> >>>>>> Hi > >>>> >>>>>> > >>>> >>>>>> Received all the files, as a first glance, the program uses at > >>>> least > >>>> >>>>>> once checkpoint mode, from the tm log, maybe we need to check > >>>> checkpoint of > >>>> >>>>>> this operator "Invoking async call Checkpoint Confirmation for > >>>> KeyedProcess > >>>> >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: > >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: > >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task > >>>> KeyedProcess -> > >>>> >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: > >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: > >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", > >>>> >>>>>> > >>>> >>>>>> Seems it took too long to complete the checkpoint (maybe > >>>> something > >>>> >>>>>> about itself, or maybe something of Kafka). I'll go through the > >>>> logs > >>>> >>>>>> carefully today or tomorrow again. > >>>> >>>>>> > >>>> >>>>>> Best, > >>>> >>>>>> Congxian > >>>> >>>>>> > >>>> >>>>>> > >>>> >>>>>> Bekir Oguz <[hidden email]> 于2019年8月6日周二 下午10:38写道: > >>>> >>>>>> > >>>> >>>>>>> Ok, I am removing apache dev group from CC. > >>>> >>>>>>> Only sending to you and my colleagues. > >>>> >>>>>>> > >>>> >>>>>>> > >>>> >>>>>>> Thanks, > >>>> >>>>>>> Bekir > >>>> >>>>>>> > >>>> >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz < > >>>> [hidden email]> > >>>> >>>>>>> het volgende geschreven: > >>>> >>>>>>> > >>>> >>>>>>> Hi Congxian, > >>>> >>>>>>> Previous email didn’t work out due to size limits. > >>>> >>>>>>> I am sending you only job manager log zipped, and will send > >>>> other > >>>> >>>>>>> info in separate email. > >>>> >>>>>>> <jobmanager_sb77v.log.zip> > >>>> >>>>>>> Regards, > >>>> >>>>>>> Bekir > >>>> >>>>>>> > >>>> >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu < > >>>> [hidden email]> > >>>> >>>>>>> het volgende geschreven: > >>>> >>>>>>> > >>>> >>>>>>> Hi Bekir > >>>> >>>>>>> > >>>> >>>>>>> Cloud you please also share the below information: > >>>> >>>>>>> - jobmanager.log > >>>> >>>>>>> - taskmanager.log(with debug info enabled) for the problematic > >>>> >>>>>>> subtask. > >>>> >>>>>>> - the DAG of your program (if can provide the skeleton program > >>>> is > >>>> >>>>>>> better -- can send to me privately) > >>>> >>>>>>> > >>>> >>>>>>> For the subIndex, maybe we can use the deploy log message in > >>>> >>>>>>> jobmanager log to identify which subtask we want. For example > >>>> in JM log, > >>>> >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO > >>>> >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - > >>>> Deploying Source: > >>>> >>>>>>> Custom Source (2/2) (attempt #0) to > >>>> >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee > >>>> >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was > >>>> deplyed to " > >>>> >>>>>>> aa.bb.cc.dd.ee" with port 39488. Sadly, there maybe still > more > >>>> than > >>>> >>>>>>> one subtasks in one contain :( > >>>> >>>>>>> > >>>> >>>>>>> Best, > >>>> >>>>>>> Congxian > >>>> >>>>>>> > >>>> >>>>>>> > >>>> >>>>>>> Bekir Oguz <[hidden email]> 于2019年8月2日周五 下午4:22写道: > >>>> >>>>>>> > >>>> >>>>>>>> Forgot to add the checkpoint details after it was complete. > >>>> This is > >>>> >>>>>>>> for that long running checkpoint with id 95632. > >>>> >>>>>>>> > >>>> >>>>>>>> <PastedGraphic-5.png> > >>>> >>>>>>>> > >>>> >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz < > >>>> [hidden email]> > >>>> >>>>>>>> het volgende geschreven: > >>>> >>>>>>>> > >>>> >>>>>>>> Hi Congxian, > >>>> >>>>>>>> I was able to fetch the logs of the task manager (attached) > >>>> and the > >>>> >>>>>>>> screenshots of the latest long checkpoint. I will get the > logs > >>>> of the job > >>>> >>>>>>>> manager for the next long running checkpoint. And also I will > >>>> try to get a > >>>> >>>>>>>> jstack during the long running checkpoint. > >>>> >>>>>>>> > >>>> >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask > >>>> numbers, > >>>> >>>>>>>> and at the Details tab of the checkpoint, we have the subtask > >>>> numbers but > >>>> >>>>>>>> not the task manager hosts, it is difficult to match those. > >>>> We’re assuming > >>>> >>>>>>>> they have the same order, so seeing that 3rd subtask is > >>>> failing, I am > >>>> >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the > >>>> task manager > >>>> >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a > >>>> great feature if > >>>> >>>>>>>> you guys also include the subtask-id’s to the Subtasks > view.*** > >>>> >>>>>>>> > >>>> >>>>>>>> Note: timestamps in the task manager log are in UTC and I am > >>>> at the > >>>> >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot > >>>> matches the time > >>>> >>>>>>>> 7:30 in the log. > >>>> >>>>>>>> > >>>> >>>>>>>> > >>>> >>>>>>>> Kind regards, > >>>> >>>>>>>> Bekir > >>>> >>>>>>>> > >>>> >>>>>>>> <task_manager.log> > >>>> >>>>>>>> > >>>> >>>>>>>> <PastedGraphic-4.png> > >>>> >>>>>>>> <PastedGraphic-3.png> > >>>> >>>>>>>> <PastedGraphic-2.png> > >>>> >>>>>>>> > >>>> >>>>>>>> > >>>> >>>>>>>> > >>>> >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu < > >>>> [hidden email]> > >>>> >>>>>>>> het volgende geschreven: > >>>> >>>>>>>> > >>>> >>>>>>>> Hi Bekir > >>>> >>>>>>>> I’ll first summary the problem here(please correct me if I’m > >>>> wrong) > >>>> >>>>>>>> 1. The same program runs on 1.6 never encounter such problems > >>>> >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other > >>>> normal > >>>> >>>>>>>> checkpoints complete less than 1 min > >>>> >>>>>>>> 3. Some bad checkpoint will have a large sync time, async > time > >>>> >>>>>>>> seems ok > >>>> >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger > than > >>>> >>>>>>>> (sync_time + async_time) > >>>> >>>>>>>> First, answer the last question, the e2e duration is > ack_time - > >>>> >>>>>>>> trigger_time, so it always bigger than (sync_time + > >>>> async_time), but we > >>>> >>>>>>>> have a big gap here, this may be problematic. > >>>> >>>>>>>> According to all the information, maybe the problem is some > >>>> task > >>>> >>>>>>>> start to do checkpoint too late and the sync checkpoint part > >>>> took some time > >>>> >>>>>>>> too long, Could you please share some more information such > >>>> below: > >>>> >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A > >>>> here) > >>>> >>>>>>>> - The detailed information of checkpoint A(includes all the > >>>> >>>>>>>> problematic subtasks) > >>>> >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic > >>>> task > >>>> >>>>>>>> and a health task > >>>> >>>>>>>> - Share the screenshot of subtasks for the problematic > >>>> >>>>>>>> task(includes the `Bytes received`, `Records received`, > `Bytes > >>>> sent`, > >>>> >>>>>>>> `Records sent` column), here wants to compare the problematic > >>>> parallelism > >>>> >>>>>>>> and good parallelism’s information, please also share the > >>>> information is > >>>> >>>>>>>> there has a data skew among the parallelisms, > >>>> >>>>>>>> - could you please share some jstacks of the problematic > >>>> >>>>>>>> parallelism — here wants to check whether the task is too > busy > >>>> to handle > >>>> >>>>>>>> the barrier. (flame graph or other things is always welcome > >>>> here) > >>>> >>>>>>>> > >>>> >>>>>>>> Best, > >>>> >>>>>>>> Congxian > >>>> >>>>>>>> > >>>> >>>>>>>> > >>>> >>>>>>>> Congxian Qiu <[hidden email]> 于2019年8月1日周四 下午8:26写道: > >>>> >>>>>>>> > >>>> >>>>>>>>> Hi Bekir > >>>> >>>>>>>>> > >>>> >>>>>>>>> I'll first comb through all the information here, and try to > >>>> find > >>>> >>>>>>>>> out the reason with you, maybe need you to share some more > >>>> information :) > >>>> >>>>>>>>> > >>>> >>>>>>>>> Best, > >>>> >>>>>>>>> Congxian > >>>> >>>>>>>>> > >>>> >>>>>>>>> > >>>> >>>>>>>>> Bekir Oguz <[hidden email]> 于2019年8月1日周四 > 下午5:00写道: > >>>> >>>>>>>>> > >>>> >>>>>>>>>> Hi Fabian, > >>>> >>>>>>>>>> Thanks for sharing this with us, but we’re already on > version > >>>> >>>>>>>>>> 1.8.1. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 > >>>> >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you > >>>> maybe give us some > >>>> >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 > >>>> minutes defined > >>>> >>>>>>>>>> somewhere in Flink? I couldn’t find one. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> In our pipeline, most of the checkpoints complete in less > >>>> than a > >>>> >>>>>>>>>> minute and some of them completed in 15 minutes+(less than > a > >>>> minute). > >>>> >>>>>>>>>> There’s definitely something which adds 15 minutes. This is > >>>> >>>>>>>>>> happening in one or more subtasks during checkpointing. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Please see the screenshot below: > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Regards, > >>>> >>>>>>>>>> Bekir > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske < > >>>> [hidden email]> > >>>> >>>>>>>>>> het volgende geschreven: > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Hi Bekir, > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 > >>>> [1]. > >>>> >>>>>>>>>> These seem to be resolved with Flink 1.8.1. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Hope this helps, > >>>> >>>>>>>>>> Fabian > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> [1] > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> > https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < > >>>> >>>>>>>>>> [hidden email]>: > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Hi Bekir > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> First of all, I think there is something wrong. the state > >>>> size > >>>> >>>>>>>>>> is almost > >>>> >>>>>>>>>> the same, but the duration is different so much. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, > >>>> then > >>>> >>>>>>>>>> copy the > >>>> >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the > >>>> sst > >>>> >>>>>>>>>> files > >>>> >>>>>>>>>> already on remote will not upload), then complete > >>>> checkpoint. Can > >>>> >>>>>>>>>> you check > >>>> >>>>>>>>>> the network bandwidth usage during checkpoint? > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Best, > >>>> >>>>>>>>>> Congxian > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Bekir Oguz <[hidden email]> 于2019年7月16日周二 > >>>> 下午10:45写道: > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Hi all, > >>>> >>>>>>>>>> We have a flink job with user state, checkpointing to > >>>> >>>>>>>>>> RocksDBBackend > >>>> >>>>>>>>>> which is externally stored in AWS S3. > >>>> >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see > >>>> >>>>>>>>>> occasionally > >>>> >>>>>>>>>> that some slots do to acknowledge the checkpoints quick > >>>> enough. > >>>> >>>>>>>>>> As an > >>>> >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except > >>>> only > >>>> >>>>>>>>>> one slot > >>>> >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to > each > >>>> >>>>>>>>>> other, like > >>>> >>>>>>>>>> 200-400 MB. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We > >>>> have > >>>> >>>>>>>>>> 5 min > >>>> >>>>>>>>>> checkpoint interval and this happens sometimes once in an > >>>> hour > >>>> >>>>>>>>>> sometimes > >>>> >>>>>>>>>> more but not in all the checkpoint requests. Please see the > >>>> >>>>>>>>>> screenshot > >>>> >>>>>>>>>> below. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Also another point: For the faulty slots, the duration is > >>>> >>>>>>>>>> consistently 15 > >>>> >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 > >>>> mins > >>>> >>>>>>>>>> response > >>>> >>>>>>>>>> time comes from. And each time it is a different task > >>>> manager, > >>>> >>>>>>>>>> not always > >>>> >>>>>>>>>> the same one. > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Do you guys aware of any other users having similar issues > >>>> with > >>>> >>>>>>>>>> the new > >>>> >>>>>>>>>> version and also a suggested bug fix or solution? > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> Thanks in advance, > >>>> >>>>>>>>>> Bekir Oguz > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>>>> > >>>> >>>>>>>> > >>>> >>>>>>>> > >>>> >>>>>>> > >>>> >>>>>>> > >>>> >>>>>> > >>>> >> > >>>> >> -- > >>>> >> -- Bekir Oguz > >>>> >> > >>>> > > >>>> > >>> > >> > >> -- > >> -- Bekir Oguz > >> > > > -- -- Bekir Oguz |
|
|
In reply to this post by Bekir Oguz
Hi Bekir
Changing the timer factory from HEAP to ROCKSDB would certainly help reduce your JVM heap usage. Since it would use RocksDB to store the timer state, you might come across performance regression as we need to poll timers from RocksDB instead of JVM heap. From our experience, 20 million timers per task manager still acts a bit too much, could you reduce your window size to reduce the timers per window? By the way, timer coalescing [1] might be an idea to reduce timers. (This method could only take effect when user register timer currently). [1] https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/operators/process_function.html#timer-coalescing Best Yun Tang ________________________________ From: Bekir Oguz <[hidden email]> Sent: Wednesday, September 11, 2019 19:39 To: Yun Tang <[hidden email]> Cc: [hidden email] <[hidden email]>; Stephan Ewen <[hidden email]>; Niels Alebregtse <[hidden email]>; Vladislav Bakayev <[hidden email]> Subject: Re: instable checkpointing after migration to flink 1.8 Hi Yun, first of all, this reported problem looks like resolved for 2 days already, right after we changed the type and number of our nodes to give more heap to task managers and have more task-managers as well. Previously, our job was configured as parallelism 70, which was distributed to 14 task-managers (5 slots/tm) each having 9GB heap. After our config change, the job is now using parallelism 100, distributed to 20 task-managers (5 slots/tm) each having 18GB heap. This job has a keyed process function which manages ~400 million records in its state, and creating 1 timer per record scheduled to trigger in 6 months to check if the record is eligible to be wiped out from state or not. So we have 400M records + 400M timers. For user state, we use RocksDB backend with incremental checkpointing enabled and using s3 as an external checkpoint location. RocksDB backend is configured with predefined FLASH_SSD_OPTIMIZED values. Before our config change, flink was managing 400M/14=28,5M records + 28,5M timers in each task-manager with 9GB heap. And after the config change, this is 400M/20=20M records + 20M timers in each task-manager with 18GB heap. So, we have less state to manage per task manager, and have more heap. Apparently this fixes(!) the problem of long checkpointing durations (15 minutes) happening occasionally. Coming back to your points: 1. Snapshot timers are indeed using HEAP which is the default. We can set it to ROCKSDB to see if that change has an impact on the end-to-end checkpoint duration. Do you think this change will also reduce the heap usage? 2. I have collected and shared those logs under /tmp directory earlier and noticed that snapshotting happens very fast, finishing in a second. But what I noticed was, compaction kicking in during the snapshotting phase of a long (15 minutes) checkpoint. But still, the time spent for snapshotting was 1 second. I guess compaction has no impact there. And still do not know why it took 15 mins to acknowledge for one task slot. I have another question regarding this problem and our use of timers. Is this a good practice to use timers like we do? Does the flink timer service support having this many timers? One timer per record, which is 400 million for us. Looks like our problem is solved for the time being, but may appear again since we still do not know the root cause. About the use of timers: Could you please share your opinion on our timer setup and maybe support us on my question on switching timers to use rocksdb instead of heap? Thanks a lot, Bekir Oguz On Thu, 5 Sep 2019 at 19:55, Yun Tang <[hidden email]<mailto:[hidden email]>> wrote: Hi Bekir From what I could see, there should be two main factors influencing your time of sync execution checkpoint within that task. 1. Snapshot timers in heap to S3 [1] (network IO) 2. Creating local RocksDB checkpoint on disk [2] (disk IO) For the first part, unfortunately, there is no log or metrics could detect how long it takes. For the second part, you could login the machine where running that task, and find logs of RocksDB (default DB folder is {io.tmp.dirs}/flink-io-xxx/job-xxx/db and the log file name is LOG). You could check the interval of logs between "Started the snapshot process -- creating snapshot in directory" and "Snapshot DONE" to know how long RocksDB takes to create checkpoint on local disk. If we configure "state.backend.rocksdb.timer-service.factory" to "ROCKSDB", we could avoid the 1st part of time and this might be a solution to your problem. But to be honest, the implementation of timer snapshot code almost stay the same for Flink-1.6 and Flink-1.8 and should not be a regression. [1] https://github.com/apache/flink/blob/ba1cd43b6ed42070fd9013159a5b65adb18b3975/flink-streaming-java/src/main/java/org/apache/flink/streaming/api/operators/AbstractStreamOperator.java#L453 [2] https://github.com/apache/flink/blob/ba1cd43b6ed42070fd9013159a5b65adb18b3975/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/snapshot/RocksIncrementalSnapshotStrategy.java#L249 Best Yun Tang ________________________________ From: Congxian Qiu <[hidden email]<mailto:[hidden email]>> Sent: Thursday, September 5, 2019 10:38 To: Bekir Oguz <[hidden email]<mailto:[hidden email]>> Cc: Stephan Ewen <[hidden email]<mailto:[hidden email]>>; dev <[hidden email]<mailto:[hidden email]>>; Niels Alebregtse <[hidden email]<mailto:[hidden email]>>; Vladislav Bakayev <[hidden email]<mailto:[hidden email]>> Subject: Re: instable checkpointing after migration to flink 1.8 Another information from our private emails there ALWAYS have Kafka AbstractCoordinator logs about lost connection to Kafka at the same time we have the checkpoints confirmed. Bekir checked the Kafka broker log, but did not find any interesting things there. Best, Congxian Congxian Qiu <[hidden email]<mailto:[hidden email]>> 于2019年9月5日周四 上午10:26写道: > Hi Bekir, > > If it is the storage place for timers, for RocksDBStateBackend, timers can > be stored in Heap or RocksDB[1][2] > [1] > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/large_state_tuning.html#tuning-rocksdb > [2] > https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/state_backends.html#rocksdb-state-backend-config-options > > Best, > Congxian > > > Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年9月4日周三 下午11:38写道: > >> Hi Stephan, >> sorry for late response. >> We indeed use timers inside a KeyedProcessFunction but the triggers of >> the timers are kinda evenly distributed, so not causing a firing storm. >> We have a custom ttl logic which is used by the deletion timer to decide >> whether delete a record from inmemory state or not. >> Can you maybe give some links to those changes in the RocksDB? >> >> Thanks in advance, >> Bekir Oguz >> >> On Fri, 30 Aug 2019 at 14:56, Stephan Ewen <[hidden email]<mailto:[hidden email]>> wrote: >> >>> Hi all! >>> >>> A thought would be that this has something to do with timers. Does the >>> task with that behavior use timers (windows, or process function)? >>> >>> If that is the case, some theories to check: >>> - Could it be a timer firing storm coinciding with a checkpoint? >>> Currently, that storm synchronously fires, checkpoints cannot preempt that, >>> which should change in 1.10 with the new mailbox model. >>> - Could the timer-async checkpointing changes have something to do >>> with that? Does some of the usually small "preparation work" (happening >>> synchronously) lead to an unwanted effect? >>> - Are you using TTL for state in that operator? >>> - There were some changes made to support timers in RocksDB recently. >>> Could that have something to do with it? >>> >>> Best, >>> Stephan >>> >>> >>> On Fri, Aug 30, 2019 at 2:45 PM Congxian Qiu <[hidden email]<mailto:[hidden email]>> >>> wrote: >>> >>>> CC flink dev mail list >>>> Update for those who may be interested in this issue, we'are still >>>> diagnosing this problem currently. >>>> >>>> Best, >>>> Congxian >>>> >>>> >>>> Congxian Qiu <[hidden email]<mailto:[hidden email]>> 于2019年8月29日周四 下午8:58写道: >>>> >>>> > Hi Bekir >>>> > >>>> > Currently, from what we have diagnosed, there is some task complete >>>> its >>>> > checkpoint too late (maybe 15 mins), but we checked the kafka broker >>>> log >>>> > and did not find any interesting things there. could we run another >>>> job, >>>> > that did not commit offset to kafka, this wants to check if it is the >>>> > "commit offset to kafka" step consumes too much time. >>>> > >>>> > Best, >>>> > Congxian >>>> > >>>> > >>>> > Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年8月28日周三 下午4:19写道: >>>> > >>>> >> Hi Congxian, >>>> >> sorry for the late reply, but no progress on this issue yet. I >>>> checked >>>> >> also the kafka broker logs, found nothing interesting there. >>>> >> And we still have 15 min duration checkpoints quite often. Any more >>>> ideas >>>> >> on where to look at? >>>> >> >>>> >> Regards, >>>> >> Bekir >>>> >> >>>> >> On Fri, 23 Aug 2019 at 12:12, Congxian Qiu <[hidden email]<mailto:[hidden email]>> >>>> >> wrote: >>>> >> >>>> >>> Hi Bekir >>>> >>> >>>> >>> Do you come back to work now, does there any more findings of this >>>> >>> problem? >>>> >>> >>>> >>> Best, >>>> >>> Congxian >>>> >>> >>>> >>> >>>> >>> Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年8月13日周二 下午4:39写道: >>>> >>> >>>> >>>> Hi Congxian, >>>> >>>> Thanks for following up this issue. It is still unresolved and I >>>> am on >>>> >>>> vacation at the moment. Hopefully my collegues Niels and Vlad can >>>> spare >>>> >>>> some time to look into this. >>>> >>>> >>>> >>>> @Niels, @Vlad: do you guys also think that this issue might be >>>> Kafka >>>> >>>> related? We could also check kafka broker logs at the time of long >>>> >>>> checkpointing. >>>> >>>> >>>> >>>> Thanks, >>>> >>>> Bekir >>>> >>>> >>>> >>>> Verstuurd vanaf mijn iPhone >>>> >>>> >>>> >>>> Op 12 aug. 2019 om 15:18 heeft Congxian Qiu < >>>> [hidden email]<mailto:[hidden email]>> >>>> >>>> het volgende geschreven: >>>> >>>> >>>> >>>> Hi Bekir >>>> >>>> >>>> >>>> Is there any progress about this problem? >>>> >>>> >>>> >>>> Best, >>>> >>>> Congxian >>>> >>>> >>>> >>>> >>>> >>>> Congxian Qiu <[hidden email]<mailto:[hidden email]>> 于2019年8月8日周四 下午11:17写道: >>>> >>>> >>>> >>>>> hi Bekir >>>> >>>>> Thanks for the information. >>>> >>>>> >>>> >>>>> - Source's checkpoint was triggered by RPC calls, so it has the >>>> >>>>> "Trigger checkpoint xxx" log, >>>> >>>>> - other task's checkpoint was triggered after received all the >>>> barrier >>>> >>>>> of upstreams, it didn't log the "Trigger checkpoint XXX" :( >>>> >>>>> >>>> >>>>> Your diagnose makes sense to me, we need to check the Kafka log. >>>> >>>>> I also find out that we always have a log like >>>> >>>>> "org.apache.kafka.clients.consumer.internals.AbstractCoordinator >>>> Marking >>>> >>>>> the coordinator 172.19.200.73:9092<http://172.19.200.73:9092> (id: 2147483646 rack: null) >>>> dead >>>> >>>>> for group userprofileaggregator >>>> >>>>> 2019-08-06 13:58:49,872 DEBUG >>>> >>>>> org.apache.flink.streaming.runtime.tasks.StreamTask - >>>> Notifica", >>>> >>>>> >>>> >>>>> I checked the doc of kafka[1], only find that the default of ` >>>> >>>>> transaction.max.timeout.ms<http://transaction.max.timeout.ms>` is 15 min >>>> >>>>> >>>> >>>>> Please let me know there you have any finds. thanks >>>> >>>>> >>>> >>>>> PS: maybe you can also checkpoint the log for task >>>> >>>>> `d0aa98767c852c97ae8faf70a54241e3`, JM received its ack message >>>> late also. >>>> >>>>> >>>> >>>>> [1] https://kafka.apache.org/documentation/ >>>> >>>>> Best, >>>> >>>>> Congxian >>>> >>>>> >>>> >>>>> >>>> >>>>> Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年8月7日周三 下午6:48写道: >>>> >>>>> >>>> >>>>>> Hi Congxian, >>>> >>>>>> Thanks for checking the logs. What I see from the logs is: >>>> >>>>>> >>>> >>>>>> - For the tasks like "Source: >>>> >>>>>> profileservice-snowplow-clean-events_kafka_source -> Filter” >>>> {17, 27, 31, >>>> >>>>>> 33, 34} / 70 : We have the ’Triggering checkpoint’ and also >>>> ‘Confirm >>>> >>>>>> checkpoint’ log lines, with 15 mins delay in between. >>>> >>>>>> - For the tasks like “KeyedProcess -> (Sink: >>>> >>>>>> profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink” {1,2,3,4,5}/70 : We >>>> DO NOT have >>>> >>>>>> the “Triggering checkpoint” log, but only the ‘Confirm >>>> checkpoint’ lines. >>>> >>>>>> >>>> >>>>>> And as a final point, we ALWAYS have Kafka AbstractCoordinator >>>> logs >>>> >>>>>> about lost connection to Kafka at the same time we have the >>>> checkpoints >>>> >>>>>> confirmed. This 15 minutes delay might be because of some >>>> timeout at the >>>> >>>>>> Kafka client (maybe 15 mins timeout), and then marking kafka >>>> coordinator >>>> >>>>>> dead, and then discovering kafka coordinator again. >>>> >>>>>> >>>> >>>>>> If the kafka connection is IDLE during 15 mins, Flink cannot >>>> confirm >>>> >>>>>> the checkpoints, cannot send the async offset commit request to >>>> Kafka. This >>>> >>>>>> could be the root cause of the problem. Please see the attached >>>> logs >>>> >>>>>> filtered on the Kafka AbstractCoordinator. Every time we have a >>>> 15 minutes >>>> >>>>>> checkpoint, we have this kafka issue. (Happened today at 9:14 >>>> and 9:52) >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> I will enable Kafka DEBUG logging to see more and let you know >>>> about >>>> >>>>>> the findings. >>>> >>>>>> >>>> >>>>>> Thanks a lot for your support, >>>> >>>>>> Bekir Oguz >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> Op 7 aug. 2019, om 12:06 heeft Congxian Qiu < >>>> [hidden email]<mailto:[hidden email]>> >>>> >>>>>> het volgende geschreven: >>>> >>>>>> >>>> >>>>>> Hi >>>> >>>>>> >>>> >>>>>> Received all the files, as a first glance, the program uses at >>>> least >>>> >>>>>> once checkpoint mode, from the tm log, maybe we need to check >>>> checkpoint of >>>> >>>>>> this operator "Invoking async call Checkpoint Confirmation for >>>> KeyedProcess >>>> >>>>>> -> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70) on task >>>> KeyedProcess -> >>>> >>>>>> (Sink: profileservice-userprofiles_kafka_sink, Sink: >>>> >>>>>> profileservice-userprofiles_kafka_deletion_marker, Sink: >>>> >>>>>> profileservice-profiledeletion_kafka_sink) (5/70)", >>>> >>>>>> >>>> >>>>>> Seems it took too long to complete the checkpoint (maybe >>>> something >>>> >>>>>> about itself, or maybe something of Kafka). I'll go through the >>>> logs >>>> >>>>>> carefully today or tomorrow again. >>>> >>>>>> >>>> >>>>>> Best, >>>> >>>>>> Congxian >>>> >>>>>> >>>> >>>>>> >>>> >>>>>> Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年8月6日周二 下午10:38写道: >>>> >>>>>> >>>> >>>>>>> Ok, I am removing apache dev group from CC. >>>> >>>>>>> Only sending to you and my colleagues. >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>>> Thanks, >>>> >>>>>>> Bekir >>>> >>>>>>> >>>> >>>>>>> Op 6 aug. 2019, om 17:33 heeft Bekir Oguz < >>>> [hidden email]<mailto:[hidden email]>> >>>> >>>>>>> het volgende geschreven: >>>> >>>>>>> >>>> >>>>>>> Hi Congxian, >>>> >>>>>>> Previous email didn’t work out due to size limits. >>>> >>>>>>> I am sending you only job manager log zipped, and will send >>>> other >>>> >>>>>>> info in separate email. >>>> >>>>>>> <jobmanager_sb77v.log.zip> >>>> >>>>>>> Regards, >>>> >>>>>>> Bekir >>>> >>>>>>> >>>> >>>>>>> Op 2 aug. 2019, om 16:37 heeft Congxian Qiu < >>>> [hidden email]<mailto:[hidden email]>> >>>> >>>>>>> het volgende geschreven: >>>> >>>>>>> >>>> >>>>>>> Hi Bekir >>>> >>>>>>> >>>> >>>>>>> Cloud you please also share the below information: >>>> >>>>>>> - jobmanager.log >>>> >>>>>>> - taskmanager.log(with debug info enabled) for the problematic >>>> >>>>>>> subtask. >>>> >>>>>>> - the DAG of your program (if can provide the skeleton program >>>> is >>>> >>>>>>> better -- can send to me privately) >>>> >>>>>>> >>>> >>>>>>> For the subIndex, maybe we can use the deploy log message in >>>> >>>>>>> jobmanager log to identify which subtask we want. For example >>>> in JM log, >>>> >>>>>>> we'll have something like "2019-08-02 11:38:47,291 INFO >>>> >>>>>>> org.apache.flink.runtime.executiongraph.ExecutionGraph - >>>> Deploying Source: >>>> >>>>>>> Custom Source (2/2) (attempt #0) to >>>> >>>>>>> container_e62_1551952890130_2071_01_000002 @ aa.bb.cc.dd.ee<http://aa.bb.cc.dd.ee> >>>> >>>>>>> (dataPort=39488)" then we know "Custum Source (2/2)" was >>>> deplyed to " >>>> >>>>>>> aa.bb.cc.dd.ee<http://aa.bb.cc.dd.ee>" with port 39488. Sadly, there maybe still more >>>> than >>>> >>>>>>> one subtasks in one contain :( >>>> >>>>>>> >>>> >>>>>>> Best, >>>> >>>>>>> Congxian >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>>> Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年8月2日周五 下午4:22写道: >>>> >>>>>>> >>>> >>>>>>>> Forgot to add the checkpoint details after it was complete. >>>> This is >>>> >>>>>>>> for that long running checkpoint with id 95632. >>>> >>>>>>>> >>>> >>>>>>>> <PastedGraphic-5.png> >>>> >>>>>>>> >>>> >>>>>>>> Op 2 aug. 2019, om 11:18 heeft Bekir Oguz < >>>> [hidden email]<mailto:[hidden email]>> >>>> >>>>>>>> het volgende geschreven: >>>> >>>>>>>> >>>> >>>>>>>> Hi Congxian, >>>> >>>>>>>> I was able to fetch the logs of the task manager (attached) >>>> and the >>>> >>>>>>>> screenshots of the latest long checkpoint. I will get the logs >>>> of the job >>>> >>>>>>>> manager for the next long running checkpoint. And also I will >>>> try to get a >>>> >>>>>>>> jstack during the long running checkpoint. >>>> >>>>>>>> >>>> >>>>>>>> Note: Since at the Subtasks tab we do not have the subtask >>>> numbers, >>>> >>>>>>>> and at the Details tab of the checkpoint, we have the subtask >>>> numbers but >>>> >>>>>>>> not the task manager hosts, it is difficult to match those. >>>> We’re assuming >>>> >>>>>>>> they have the same order, so seeing that 3rd subtask is >>>> failing, I am >>>> >>>>>>>> getting the 3rd line at the Subtasks tab which leads to the >>>> task manager >>>> >>>>>>>> host flink-taskmanager-84ccd5bddf-2cbxn. ***It would be a >>>> great feature if >>>> >>>>>>>> you guys also include the subtask-id’s to the Subtasks view.*** >>>> >>>>>>>> >>>> >>>>>>>> Note: timestamps in the task manager log are in UTC and I am >>>> at the >>>> >>>>>>>> moment at zone UTC+3, so the time 10:30 at the screenshot >>>> matches the time >>>> >>>>>>>> 7:30 in the log. >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Kind regards, >>>> >>>>>>>> Bekir >>>> >>>>>>>> >>>> >>>>>>>> <task_manager.log> >>>> >>>>>>>> >>>> >>>>>>>> <PastedGraphic-4.png> >>>> >>>>>>>> <PastedGraphic-3.png> >>>> >>>>>>>> <PastedGraphic-2.png> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Op 2 aug. 2019, om 07:23 heeft Congxian Qiu < >>>> [hidden email]<mailto:[hidden email]>> >>>> >>>>>>>> het volgende geschreven: >>>> >>>>>>>> >>>> >>>>>>>> Hi Bekir >>>> >>>>>>>> I’ll first summary the problem here(please correct me if I’m >>>> wrong) >>>> >>>>>>>> 1. The same program runs on 1.6 never encounter such problems >>>> >>>>>>>> 2. Some checkpoints completed too long (15+ min), but other >>>> normal >>>> >>>>>>>> checkpoints complete less than 1 min >>>> >>>>>>>> 3. Some bad checkpoint will have a large sync time, async time >>>> >>>>>>>> seems ok >>>> >>>>>>>> 4. Some bad checkpoint, the e2e duration will much bigger than >>>> >>>>>>>> (sync_time + async_time) >>>> >>>>>>>> First, answer the last question, the e2e duration is ack_time - >>>> >>>>>>>> trigger_time, so it always bigger than (sync_time + >>>> async_time), but we >>>> >>>>>>>> have a big gap here, this may be problematic. >>>> >>>>>>>> According to all the information, maybe the problem is some >>>> task >>>> >>>>>>>> start to do checkpoint too late and the sync checkpoint part >>>> took some time >>>> >>>>>>>> too long, Could you please share some more information such >>>> below: >>>> >>>>>>>> - A Screenshot of summary for one bad checkpoint(we call it A >>>> here) >>>> >>>>>>>> - The detailed information of checkpoint A(includes all the >>>> >>>>>>>> problematic subtasks) >>>> >>>>>>>> - Jobmanager.log and the taskmanager.log for the problematic >>>> task >>>> >>>>>>>> and a health task >>>> >>>>>>>> - Share the screenshot of subtasks for the problematic >>>> >>>>>>>> task(includes the `Bytes received`, `Records received`, `Bytes >>>> sent`, >>>> >>>>>>>> `Records sent` column), here wants to compare the problematic >>>> parallelism >>>> >>>>>>>> and good parallelism’s information, please also share the >>>> information is >>>> >>>>>>>> there has a data skew among the parallelisms, >>>> >>>>>>>> - could you please share some jstacks of the problematic >>>> >>>>>>>> parallelism ― here wants to check whether the task is too busy >>>> to handle >>>> >>>>>>>> the barrier. (flame graph or other things is always welcome >>>> here) >>>> >>>>>>>> >>>> >>>>>>>> Best, >>>> >>>>>>>> Congxian >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> Congxian Qiu <[hidden email]<mailto:[hidden email]>> 于2019年8月1日周四 下午8:26写道: >>>> >>>>>>>> >>>> >>>>>>>>> Hi Bekir >>>> >>>>>>>>> >>>> >>>>>>>>> I'll first comb through all the information here, and try to >>>> find >>>> >>>>>>>>> out the reason with you, maybe need you to share some more >>>> information :) >>>> >>>>>>>>> >>>> >>>>>>>>> Best, >>>> >>>>>>>>> Congxian >>>> >>>>>>>>> >>>> >>>>>>>>> >>>> >>>>>>>>> Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年8月1日周四 下午5:00写道: >>>> >>>>>>>>> >>>> >>>>>>>>>> Hi Fabian, >>>> >>>>>>>>>> Thanks for sharing this with us, but we’re already on version >>>> >>>>>>>>>> 1.8.1. >>>> >>>>>>>>>> >>>> >>>>>>>>>> What I don’t understand is which mechanism in Flink adds 15 >>>> >>>>>>>>>> minutes to the checkpoint duration occasionally. Can you >>>> maybe give us some >>>> >>>>>>>>>> hints on where to look at? Is there a default timeout of 15 >>>> minutes defined >>>> >>>>>>>>>> somewhere in Flink? I couldn’t find one. >>>> >>>>>>>>>> >>>> >>>>>>>>>> In our pipeline, most of the checkpoints complete in less >>>> than a >>>> >>>>>>>>>> minute and some of them completed in 15 minutes+(less than a >>>> minute). >>>> >>>>>>>>>> There’s definitely something which adds 15 minutes. This is >>>> >>>>>>>>>> happening in one or more subtasks during checkpointing. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Please see the screenshot below: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Regards, >>>> >>>>>>>>>> Bekir >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Op 23 jul. 2019, om 16:37 heeft Fabian Hueske < >>>> [hidden email]<mailto:[hidden email]>> >>>> >>>>>>>>>> het volgende geschreven: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi Bekir, >>>> >>>>>>>>>> >>>> >>>>>>>>>> Another user reported checkpointing issues with Flink 1.8.0 >>>> [1]. >>>> >>>>>>>>>> These seem to be resolved with Flink 1.8.1. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hope this helps, >>>> >>>>>>>>>> Fabian >>>> >>>>>>>>>> >>>> >>>>>>>>>> [1] >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> https://lists.apache.org/thread.html/991fe3b09fd6a052ff52e5f7d9cdd9418545e68b02e23493097d9bc4@%3Cuser.flink.apache.org%3E >>>> >>>>>>>>>> >>>> >>>>>>>>>> Am Mi., 17. Juli 2019 um 09:16 Uhr schrieb Congxian Qiu < >>>> >>>>>>>>>> [hidden email]<mailto:[hidden email]>>: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi Bekir >>>> >>>>>>>>>> >>>> >>>>>>>>>> First of all, I think there is something wrong. the state >>>> size >>>> >>>>>>>>>> is almost >>>> >>>>>>>>>> the same, but the duration is different so much. >>>> >>>>>>>>>> >>>> >>>>>>>>>> The checkpoint for RocksDBStatebackend is dump sst files, >>>> then >>>> >>>>>>>>>> copy the >>>> >>>>>>>>>> needed sst files(if you enable incremental checkpoint, the >>>> sst >>>> >>>>>>>>>> files >>>> >>>>>>>>>> already on remote will not upload), then complete >>>> checkpoint. Can >>>> >>>>>>>>>> you check >>>> >>>>>>>>>> the network bandwidth usage during checkpoint? >>>> >>>>>>>>>> >>>> >>>>>>>>>> Best, >>>> >>>>>>>>>> Congxian >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Bekir Oguz <[hidden email]<mailto:[hidden email]>> 于2019年7月16日周二 >>>> 下午10:45写道: >>>> >>>>>>>>>> >>>> >>>>>>>>>> Hi all, >>>> >>>>>>>>>> We have a flink job with user state, checkpointing to >>>> >>>>>>>>>> RocksDBBackend >>>> >>>>>>>>>> which is externally stored in AWS S3. >>>> >>>>>>>>>> After we have migrated our cluster from 1.6 to 1.8, we see >>>> >>>>>>>>>> occasionally >>>> >>>>>>>>>> that some slots do to acknowledge the checkpoints quick >>>> enough. >>>> >>>>>>>>>> As an >>>> >>>>>>>>>> example: All slots acknowledge between 30-50 seconds except >>>> only >>>> >>>>>>>>>> one slot >>>> >>>>>>>>>> acknowledges in 15 mins. Checkpoint sizes are similar to each >>>> >>>>>>>>>> other, like >>>> >>>>>>>>>> 200-400 MB. >>>> >>>>>>>>>> >>>> >>>>>>>>>> We did not experience this weird behaviour in Flink 1.6. We >>>> have >>>> >>>>>>>>>> 5 min >>>> >>>>>>>>>> checkpoint interval and this happens sometimes once in an >>>> hour >>>> >>>>>>>>>> sometimes >>>> >>>>>>>>>> more but not in all the checkpoint requests. Please see the >>>> >>>>>>>>>> screenshot >>>> >>>>>>>>>> below. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Also another point: For the faulty slots, the duration is >>>> >>>>>>>>>> consistently 15 >>>> >>>>>>>>>> mins and some seconds, we couldn’t find out where this 15 >>>> mins >>>> >>>>>>>>>> response >>>> >>>>>>>>>> time comes from. And each time it is a different task >>>> manager, >>>> >>>>>>>>>> not always >>>> >>>>>>>>>> the same one. >>>> >>>>>>>>>> >>>> >>>>>>>>>> Do you guys aware of any other users having similar issues >>>> with >>>> >>>>>>>>>> the new >>>> >>>>>>>>>> version and also a suggested bug fix or solution? >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> Thanks in advance, >>>> >>>>>>>>>> Bekir Oguz >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>>>> >>>> >>>>>>>> >>>> >>>>>>>> >>>> >>>>>>> >>>> >>>>>>> >>>> >>>>>> >>>> >> >>>> >> -- >>>> >> -- Bekir Oguz >>>> >> >>>> > >>>> >>> >> >> -- >> -- Bekir Oguz >> > -- -- Bekir Oguz |
«
Return to (DEPRECATED) Apache Flink Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |