Using FileSystem SQL Connector to Commit Hive Partition Exception


|
https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html <https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html>
Here is my code: my datastream source: ``` public static class MySource implements SourceFunction<UserInfo>{ String userids[] = { "4760858d-2bec-483c-a535-291de04b2247", "67088699-d4f4-43f2-913c-481bff8a2dc5", "72f7b6a8-e1a9-49b4-9a0b-770c41e01bfb", "dfa27cb6-bd94-4bc0-a90b-f7beeb9faa8b", "aabbaa50-72f4-495c-b3a1-70383ee9d6a4", "3218bbb9-5874-4d37-a82d-3e35e52d1702", "3ebfb9602ac07779||3ebfe9612a007979", "aec20d52-c2eb-4436-b121-c29ad4097f6c", "e7e896cd939685d7||e7e8e6c1930689d7", "a4b1e1db-55ef-4d9d-b9d2-18393c5f59ee" }; @Override public void run(SourceContext<UserInfo> sourceContext) throws Exception{ while (true){ String userid = userids[(int) (Math.random() * (userids.length - 1))]; UserInfo userInfo = new UserInfo(); userInfo.setUserId(userid); userInfo.setAmount(Math.random() * 100); userInfo.setTs(new Timestamp(System.currentTimeMillis())); sourceContext.collect(userInfo); Thread.sleep(100); } } @Override public void cancel(){ } } public static class UserInfo implements java.io.Serializable{ private String userId; private Double amount; private Timestamp ts; public String getUserId(){ return userId; } public void setUserId(String userId){ this.userId = userId; } public Double getAmount(){ return amount; } public void setAmount(Double amount){ this.amount = amount; } public Timestamp getTs(){ return ts; } public void setTs(Timestamp ts){ this.ts = ts; } } ``` flink code: ``` StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment(); bsEnv.enableCheckpointing(10000); StreamTableEnvironment tEnv = StreamTableEnvironment.create(bsEnv); DataStream<UserInfo> dataStream = bsEnv.addSource(new MySource()) //构造hive catalog String name = "myhive"; String defaultDatabase = "default"; String hiveConfDir = "/Users/user/work/hive/conf"; // a local path String version = "3.1.2"; HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version); tEnv.registerCatalog("myhive", hive); tEnv.useCatalog("myhive"); tEnv.getConfig().setSqlDialect(SqlDialect.HIVE); tEnv.useDatabase("db1"); tEnv.createTemporaryView("users", dataStream); String hiveSql = "CREATE external TABLE fs_table (\n" + " user_id STRING,\n" + " order_amount DOUBLE" + ") partitioned by (dt string,h string,m string) " + "stored as ORC " + "TBLPROPERTIES (\n" + " 'partition.time-extractor.timestamp-pattern'='$dt $h:$m:00',\n" + " 'sink.partition-commit.delay'='0s',\n" + " 'sink.partition-commit.trigger'='partition-time',\n" + " 'sink.partition-commit.policy.kind'='metastore'" + ")"; tEnv.executeSql(hiveSql); String insertSql = "SELECT * FROM users"; tEnv.executeSql(insertSql); ``` And this is my flink configuration: ``` jobmanager.memory.process.size: 1600m taskmanager.memory.process.size 4096m taskmanager.numberOfTaskSlots: 1 parallelism.default: 1 ``` And the exception is: java.util.concurrent.completionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailable and request to ResourceManager for new slot failed. According the exception message, it means the resource is in sufficient, but the hadoop resource is enough, memory is 300+g, cores is 72, and the usage rate is lower about 30%. I have tried increase the taskmanager slot at flink run command with `flink run -ys`, but it is not effective. Here is the environment: flink version: 1.12.0 java: 1.8 Please check what’s the problem is, really appreciate it. Thanks. |
Re: Using FileSystem SQL Connector to Commit Hive Partition Exception
|
|
Hi Chenzuoli,
the exception says that Flink could not allocate enough slots. Could you share the DEBUG logs of the run with us. They should contain the reason why the allocation of further resources failed. Cheers, Till On Sun, Apr 11, 2021 at 5:59 AM chenzuoli <[hidden email]> wrote: > > https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html > < > https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html > > > Here is my code: > my datastream source: > ``` > public static class MySource implements SourceFunction<UserInfo>{ > > String userids[] = { > "4760858d-2bec-483c-a535-291de04b2247", > "67088699-d4f4-43f2-913c-481bff8a2dc5", > "72f7b6a8-e1a9-49b4-9a0b-770c41e01bfb", > "dfa27cb6-bd94-4bc0-a90b-f7beeb9faa8b", > "aabbaa50-72f4-495c-b3a1-70383ee9d6a4", > "3218bbb9-5874-4d37-a82d-3e35e52d1702", > "3ebfb9602ac07779||3ebfe9612a007979", > "aec20d52-c2eb-4436-b121-c29ad4097f6c", > "e7e896cd939685d7||e7e8e6c1930689d7", > "a4b1e1db-55ef-4d9d-b9d2-18393c5f59ee" > }; > > @Override > public void run(SourceContext<UserInfo> sourceContext) throws > Exception{ > > while (true){ > String userid = userids[(int) (Math.random() * (userids.length > - 1))]; > UserInfo userInfo = new UserInfo(); > userInfo.setUserId(userid); > userInfo.setAmount(Math.random() * 100); > userInfo.setTs(new Timestamp(System.currentTimeMillis())); > sourceContext.collect(userInfo); > Thread.sleep(100); > } > } > > @Override > public void cancel(){ > > } > } > > public static class UserInfo implements java.io.Serializable{ > private String userId; > private Double amount; > private Timestamp ts; > > public String getUserId(){ > return userId; > } > > public void setUserId(String userId){ > this.userId = userId; > } > > public Double getAmount(){ > return amount; > } > > public void setAmount(Double amount){ > this.amount = amount; > } > > public Timestamp getTs(){ > return ts; > } > > public void setTs(Timestamp ts){ > this.ts = ts; > } > } > ``` > > flink code: > ``` > StreamExecutionEnvironment bsEnv = > StreamExecutionEnvironment.getExecutionEnvironment(); > bsEnv.enableCheckpointing(10000); > StreamTableEnvironment tEnv = StreamTableEnvironment.create(bsEnv); > DataStream<UserInfo> dataStream = bsEnv.addSource(new MySource()) > > //构造hive catalog > String name = "myhive"; > String defaultDatabase = "default"; > String hiveConfDir = "/Users/user/work/hive/conf"; // a local path > String version = "3.1.2"; > > HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, > version); > tEnv.registerCatalog("myhive", hive); > tEnv.useCatalog("myhive"); > tEnv.getConfig().setSqlDialect(SqlDialect.HIVE); > tEnv.useDatabase("db1"); > > tEnv.createTemporaryView("users", dataStream); > > String hiveSql = "CREATE external TABLE fs_table (\n" + > " user_id STRING,\n" + > " order_amount DOUBLE" + > ") partitioned by (dt string,h string,m string) " + > "stored as ORC " + > "TBLPROPERTIES (\n" + > " 'partition.time-extractor.timestamp-pattern'='$dt $h:$m:00',\n" + > " 'sink.partition-commit.delay'='0s',\n" + > " 'sink.partition-commit.trigger'='partition-time',\n" + > " 'sink.partition-commit.policy.kind'='metastore'" + > ")"; > tEnv.executeSql(hiveSql); > > String insertSql = "SELECT * FROM users"; > tEnv.executeSql(insertSql); > ``` > > And this is my flink configuration: > ``` > jobmanager.memory.process.size: 1600m > taskmanager.memory.process.size 4096m > taskmanager.numberOfTaskSlots: 1 > parallelism.default: 1 > ``` > > And the exception is: java.util.concurrent.completionException: > org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailable and > request to ResourceManager for new slot failed. > > According the exception message, it means the resource is in sufficient, > but the hadoop resource is enough, memory is 300+g, cores is 72, and the > usage rate is lower about 30%. > > I have tried increase the taskmanager slot at flink run command with > `flink run -ys`, but it is not effective. > > Here is the environment: > flink version: 1.12.0 > java: 1.8 > > Please check what’s the problem is, really appreciate it. Thanks. > > > > > > > > > > > > > > > > > > |
|
|
Download full resolution images Available until May 14, 2021 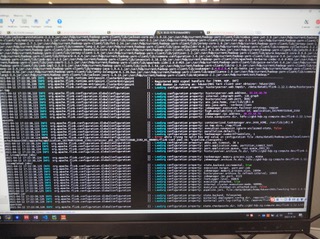 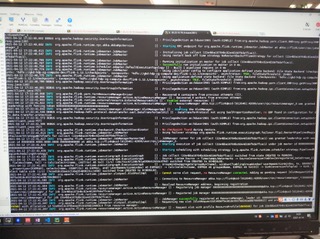 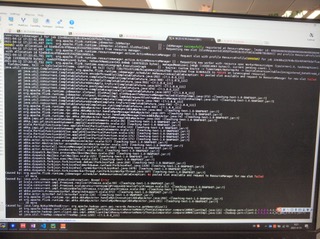 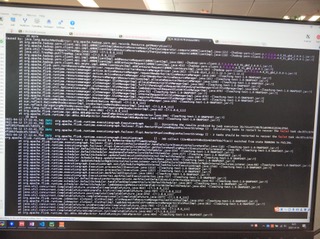 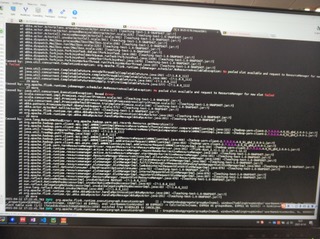 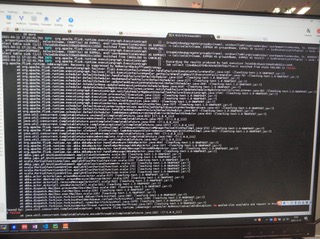
|
Re: Using FileSystem SQL Connector to Commit Hive Partition Exception
|
|
Hi Chenzuoli, The pictures are unfortunately not readable for me. Cheers, Till On Wed, Apr 14, 2021 at 3:31 AM chenzuoli <[hidden email]> wrote:
|
Re: Using FileSystem SQL Connector to Commit Hive Partition Exception
|
|
Hi Chenzuoli,
it seems that you are using Windows 10, you could follow this page to improve the screenshots quality: https://support.microsoft.com/en-us/windows/open-snipping-tool-and-take-a-screenshot-a35ac9ff-4a58-24c9-3253-f12bac9f9d44#:~:text=To%20open%20the%20Snipping%20Tool,Snip%2C%20and%20then%20press%20Enter. Best regards, Alessandro On Wed, 14 Apr 2021 at 10:11, Till Rohrmann <[hidden email]> wrote: > Hi Chenzuoli, > > The pictures are unfortunately not readable for me. > > Cheers, > Till > > On Wed, Apr 14, 2021 at 3:31 AM chenzuoli <[hidden email]> wrote: > >> Download full resolution images >> Available until May 14, 2021 >> >> <https://www.icloud.com/attachment/?u=https%3A%2F%2Fcvws.icloud-content.com%2FB%2FAe5GSkj-YFuZTCZGaEu6GPihzx-7AdUBnM39Y4MbYWsiYk_NLx9zwJQQ%2F%24%7Bf%7D%3Fo%3DAlVY5QSsW5BX_oH9EoZOHG6QkCn05TIH8YH2miB0n_C5%26v%3D1%26x%3D3%26a%3DCAog36C0QwaK0BMfOhUFlqSplqI58eCIbiUgrnvfRrdbAn4SehDC8IDwjC8YwoD8w5YvIgEAKgkC6AMA_28vpaVSBKHPH7taBHPAlBBqJ2K-nETHh5awW3rtW5dSHzC3nDeIuqPUTZUvvcdtgOsNFwfHj7kUjHInHPbS8K9O0MrgZn-fA2aEEVj-bpqvfyInTOhEsY1j-6TEPySAjMS0%26e%3D1620955824%26fl%3D%26r%3D7464B4A1-AC88-496E-9608-6D9FEB86BFEA-1%26k%3D%24%7Buk%7D%26ckc%3Dcom.apple.largeattachment%26ckz%3DB0F3D90A-B949-4097-AD3F-ACE30FBE5D19%26p%3D30%26s%3Db1YldRmDMqM72hNP9DLBbOpRbOU&uk=Ir8SHK-FfM36NNDgmyiaYg&f=Images.zip&sz=42860073>Hi, >> sorry for the debug log, I can take the photos instead of the log text >> because of company policy, so if there is any log not clear, please tell >> me. Thanks. >> >> >> >> >> >> >> >> >> >> On Apr 12, 2021, at 16:06, Till Rohrmann <[hidden email]> wrote: >> >> Hi Chenzuoli, >> >> the exception says that Flink could not allocate enough slots. Could you >> share the DEBUG logs of the run with us. They should contain the reason >> why >> the allocation of further resources failed. >> >> Cheers, >> Till >> >> On Sun, Apr 11, 2021 at 5:59 AM chenzuoli <[hidden email]> wrote: >> >> >> >> https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html >> < >> >> https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html >> >> >> Here is my code: >> my datastream source: >> ``` >> public static class MySource implements SourceFunction<UserInfo>{ >> >> String userids[] = { >> "4760858d-2bec-483c-a535-291de04b2247", >> "67088699-d4f4-43f2-913c-481bff8a2dc5", >> "72f7b6a8-e1a9-49b4-9a0b-770c41e01bfb", >> "dfa27cb6-bd94-4bc0-a90b-f7beeb9faa8b", >> "aabbaa50-72f4-495c-b3a1-70383ee9d6a4", >> "3218bbb9-5874-4d37-a82d-3e35e52d1702", >> "3ebfb9602ac07779||3ebfe9612a007979", >> "aec20d52-c2eb-4436-b121-c29ad4097f6c", >> "e7e896cd939685d7||e7e8e6c1930689d7", >> "a4b1e1db-55ef-4d9d-b9d2-18393c5f59ee" >> }; >> >> @Override >> public void run(SourceContext<UserInfo> sourceContext) throws >> Exception{ >> >> while (true){ >> String userid = userids[(int) (Math.random() * (userids.length >> - 1))]; >> UserInfo userInfo = new UserInfo(); >> userInfo.setUserId(userid); >> userInfo.setAmount(Math.random() * 100); >> userInfo.setTs(new Timestamp(System.currentTimeMillis())); >> sourceContext.collect(userInfo); >> Thread.sleep(100); >> } >> } >> >> @Override >> public void cancel(){ >> >> } >> } >> >> public static class UserInfo implements java.io.Serializable{ >> private String userId; >> private Double amount; >> private Timestamp ts; >> >> public String getUserId(){ >> return userId; >> } >> >> public void setUserId(String userId){ >> this.userId = userId; >> } >> >> public Double getAmount(){ >> return amount; >> } >> >> public void setAmount(Double amount){ >> this.amount = amount; >> } >> >> public Timestamp getTs(){ >> return ts; >> } >> >> public void setTs(Timestamp ts){ >> this.ts = ts; >> } >> } >> ``` >> >> flink code: >> ``` >> StreamExecutionEnvironment bsEnv = >> StreamExecutionEnvironment.getExecutionEnvironment(); >> bsEnv.enableCheckpointing(10000); >> StreamTableEnvironment tEnv = StreamTableEnvironment.create(bsEnv); >> DataStream<UserInfo> dataStream = bsEnv.addSource(new MySource()) >> >> //构造hive catalog >> String name = "myhive"; >> String defaultDatabase = "default"; >> String hiveConfDir = "/Users/user/work/hive/conf"; // a local path >> String version = "3.1.2"; >> >> HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, >> version); >> tEnv.registerCatalog("myhive", hive); >> tEnv.useCatalog("myhive"); >> tEnv.getConfig().setSqlDialect(SqlDialect.HIVE); >> tEnv.useDatabase("db1"); >> >> tEnv.createTemporaryView("users", dataStream); >> >> String hiveSql = "CREATE external TABLE fs_table (\n" + >> " user_id STRING,\n" + >> " order_amount DOUBLE" + >> ") partitioned by (dt string,h string,m string) " + >> "stored as ORC " + >> "TBLPROPERTIES (\n" + >> " 'partition.time-extractor.timestamp-pattern'='$dt $h:$m:00',\n" + >> " 'sink.partition-commit.delay'='0s',\n" + >> " 'sink.partition-commit.trigger'='partition-time',\n" + >> " 'sink.partition-commit.policy.kind'='metastore'" + >> ")"; >> tEnv.executeSql(hiveSql); >> >> String insertSql = "SELECT * FROM users"; >> tEnv.executeSql(insertSql); >> ``` >> >> And this is my flink configuration: >> ``` >> jobmanager.memory.process.size: 1600m >> taskmanager.memory.process.size 4096m >> taskmanager.numberOfTaskSlots: 1 >> parallelism.default: 1 >> ``` >> >> And the exception is: java.util.concurrent.completionException: >> org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailable and >> request to ResourceManager for new slot failed. >> >> According the exception message, it means the resource is in sufficient, >> but the hadoop resource is enough, memory is 300+g, cores is 72, and the >> usage rate is lower about 30%. >> >> I have tried increase the taskmanager slot at flink run command with >> `flink run -ys`, but it is not effective. >> >> Here is the environment: >> flink version: 1.12.0 >> java: 1.8 >> >> Please check what’s the problem is, really appreciate it. Thanks. >> >> >> >> >> >> >> >> >> >> >> >> >> >> >> >> >> >> >> >> |
|
|
Download full resolution images Available until May 14, 2021 Sorry for the pictures, I cannot get out the screenshots or text from the company’s desktop, here is the new clear pictures 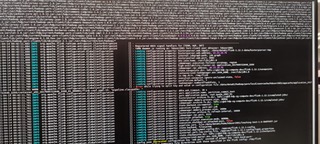 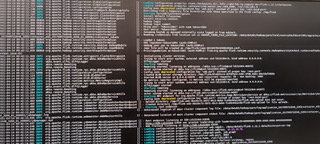 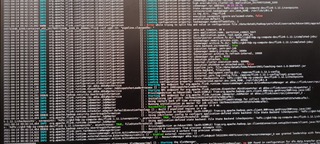      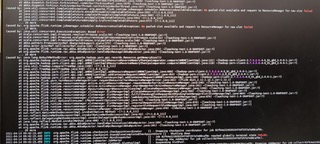
|
|
|
Hi:
This is the log attachment: https://www.icloud.com/attachment/?u=https%3A%2F%2Fcvws.icloud-content.com%2FB%2FAe5GSkj-YFuZTCZGaEu6GPihzx-7AdUBnM39Y4MbYWsiYk_NLx9zwJQQ%2F%24%7Bf%7D%3Fo%3DAlVY5QSsW5BX_oH9EoZOHG6QkCn05TIH8YH2miB0n_C5%26v%3D1%26x%3D3%26a%3DCAog36C0QwaK0BMfOhUFlqSplqI58eCIbiUgrnvfRrdbAn4SehDC8IDwjC8YwoD8w5YvIgEAKgkC6AMA_28vpaVSBKHPH7taBHPAlBBqJ2K-nETHh5awW3rtW5dSHzC3nDeIuqPUTZUvvcdtgOsNFwfHj7kUjHInHPbS8K9O0MrgZn-fA2aEEVj-bpqvfyInTOhEsY1j-6TEPySAjMS0%26e%3D1620955824%26fl%3D%26r%3D7464B4A1-AC88-496E-9608-6D9FEB86BFEA-1%26k%3D%24%7Buk%7D%26ckc%3Dcom.apple.largeattachment%26ckz%3DB0F3D90A-B949-4097-AD3F-ACE30FBE5D19%26p%3D30%26s%3Db1YldRmDMqM72hNP9DLBbOpRbOU&uk=Ir8SHK-FfM36NNDgmyiaYg&f=Images.zip&sz=42860073 > On Apr 14, 2021, at 17:06, chenzuoli <[hidden email]> wrote: > > Hi, > > Sorry for the pictures, I cannot get out the screenshots or text from the company’s desktop, here is the new clear pictures > > > <PastedGraphic-8.png><PastedGraphic-9.png><PastedGraphic-10.png><PastedGraphic-11.png><PastedGraphic-12.png><PastedGraphic-13.png><PastedGraphic-14.png><PastedGraphic-15.png><PastedGraphic-16.png> > > > > > >> On Apr 14, 2021, at 16:17, Alessandro Solimando <[hidden email] <mailto:[hidden email]>> wrote: >> >> Hi Chenzuoli, >> it seems that you are using Windows 10, you could follow this page to >> improve the screenshots quality: >> https://support.microsoft.com/en-us/windows/open-snipping-tool-and-take-a-screenshot-a35ac9ff-4a58-24c9-3253-f12bac9f9d44#:~:text=To%20open%20the%20Snipping%20Tool,Snip%2C%20and%20then%20press%20Enter <https://support.microsoft.com/en-us/windows/open-snipping-tool-and-take-a-screenshot-a35ac9ff-4a58-24c9-3253-f12bac9f9d44#:~:text=To%20open%20the%20Snipping%20Tool,Snip%2C%20and%20then%20press%20Enter>. >> >> Best regards, >> Alessandro >> >> On Wed, 14 Apr 2021 at 10:11, Till Rohrmann <[hidden email] <mailto:[hidden email]>> wrote: >> >>> Hi Chenzuoli, >>> >>> The pictures are unfortunately not readable for me. >>> >>> Cheers, >>> Till >>> >>> On Wed, Apr 14, 2021 at 3:31 AM chenzuoli <[hidden email] <mailto:[hidden email]>> wrote: >>> >>>> Download full resolution images >>>> Available until May 14, 2021 >>>> >>>> <https://www.icloud.com/attachment/?u=https%3A%2F%2Fcvws.icloud-content.com%2FB%2FAe5GSkj-YFuZTCZGaEu6GPihzx-7AdUBnM39Y4MbYWsiYk_NLx9zwJQQ%2F%24%7Bf%7D%3Fo%3DAlVY5QSsW5BX_oH9EoZOHG6QkCn05TIH8YH2miB0n_C5%26v%3D1%26x%3D3%26a%3DCAog36C0QwaK0BMfOhUFlqSplqI58eCIbiUgrnvfRrdbAn4SehDC8IDwjC8YwoD8w5YvIgEAKgkC6AMA_28vpaVSBKHPH7taBHPAlBBqJ2K-nETHh5awW3rtW5dSHzC3nDeIuqPUTZUvvcdtgOsNFwfHj7kUjHInHPbS8K9O0MrgZn-fA2aEEVj-bpqvfyInTOhEsY1j-6TEPySAjMS0%26e%3D1620955824%26fl%3D%26r%3D7464B4A1-AC88-496E-9608-6D9FEB86BFEA-1%26k%3D%24%7Buk%7D%26ckc%3Dcom.apple.largeattachment%26ckz%3DB0F3D90A-B949-4097-AD3F-ACE30FBE5D19%26p%3D30%26s%3Db1YldRmDMqM72hNP9DLBbOpRbOU&uk=Ir8SHK-FfM36NNDgmyiaYg&f=Images.zip&sz=42860073 <https://www.icloud.com/attachment/?u=https%3A%2F%2Fcvws.icloud-content.com%2FB%2FAe5GSkj-YFuZTCZGaEu6GPihzx-7AdUBnM39Y4MbYWsiYk_NLx9zwJQQ%2F%24%7Bf%7D%3Fo%3DAlVY5QSsW5BX_oH9EoZOHG6QkCn05TIH8YH2miB0n_C5%26v%3D1%26x%3D3%26a%3DCAog36C0QwaK0BMfOhUFlqSplqI58eCIbiUgrnvfRrdbAn4SehDC8IDwjC8YwoD8w5YvIgEAKgkC6AMA_28vpaVSBKHPH7taBHPAlBBqJ2K-nETHh5awW3rtW5dSHzC3nDeIuqPUTZUvvcdtgOsNFwfHj7kUjHInHPbS8K9O0MrgZn-fA2aEEVj-bpqvfyInTOhEsY1j-6TEPySAjMS0%26e%3D1620955824%26fl%3D%26r%3D7464B4A1-AC88-496E-9608-6D9FEB86BFEA-1%26k%3D%24%7Buk%7D%26ckc%3Dcom.apple.largeattachment%26ckz%3DB0F3D90A-B949-4097-AD3F-ACE30FBE5D19%26p%3D30%26s%3Db1YldRmDMqM72hNP9DLBbOpRbOU&uk=Ir8SHK-FfM36NNDgmyiaYg&f=Images.zip&sz=42860073>>Hi, >>>> sorry for the debug log, I can take the photos instead of the log text >>>> because of company policy, so if there is any log not clear, please tell >>>> me. Thanks. >>>> >>>> >>>> >>>> >>>> >>>> >>>> >>>> >>>> >>>> On Apr 12, 2021, at 16:06, Till Rohrmann <[hidden email] <mailto:[hidden email]>> wrote: >>>> >>>> Hi Chenzuoli, >>>> >>>> the exception says that Flink could not allocate enough slots. Could you >>>> share the DEBUG logs of the run with us. They should contain the reason >>>> why >>>> the allocation of further resources failed. >>>> >>>> Cheers, >>>> Till >>>> >>>> On Sun, Apr 11, 2021 at 5:59 AM chenzuoli <[hidden email] <mailto:[hidden email]>> wrote: >>>> >>>> >>>> >>>> https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html <https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html> >>>> < >>>> >>>> https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html <https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html> >>>> >>>> >>>> Here is my code: >>>> my datastream source: >>>> ``` >>>> public static class MySource implements SourceFunction<UserInfo>{ >>>> >>>> String userids[] = { >>>> "4760858d-2bec-483c-a535-291de04b2247", >>>> "67088699-d4f4-43f2-913c-481bff8a2dc5", >>>> "72f7b6a8-e1a9-49b4-9a0b-770c41e01bfb", >>>> "dfa27cb6-bd94-4bc0-a90b-f7beeb9faa8b", >>>> "aabbaa50-72f4-495c-b3a1-70383ee9d6a4", >>>> "3218bbb9-5874-4d37-a82d-3e35e52d1702", >>>> "3ebfb9602ac07779||3ebfe9612a007979", >>>> "aec20d52-c2eb-4436-b121-c29ad4097f6c", >>>> "e7e896cd939685d7||e7e8e6c1930689d7", >>>> "a4b1e1db-55ef-4d9d-b9d2-18393c5f59ee" >>>> }; >>>> >>>> @Override >>>> public void run(SourceContext<UserInfo> sourceContext) throws >>>> Exception{ >>>> >>>> while (true){ >>>> String userid = userids[(int) (Math.random() * (userids.length >>>> - 1))]; >>>> UserInfo userInfo = new UserInfo(); >>>> userInfo.setUserId(userid); >>>> userInfo.setAmount(Math.random() * 100); >>>> userInfo.setTs(new Timestamp(System.currentTimeMillis())); >>>> sourceContext.collect(userInfo); >>>> Thread.sleep(100); >>>> } >>>> } >>>> >>>> @Override >>>> public void cancel(){ >>>> >>>> } >>>> } >>>> >>>> public static class UserInfo implements java.io.Serializable{ >>>> private String userId; >>>> private Double amount; >>>> private Timestamp ts; >>>> >>>> public String getUserId(){ >>>> return userId; >>>> } >>>> >>>> public void setUserId(String userId){ >>>> this.userId = userId; >>>> } >>>> >>>> public Double getAmount(){ >>>> return amount; >>>> } >>>> >>>> public void setAmount(Double amount){ >>>> this.amount = amount; >>>> } >>>> >>>> public Timestamp getTs(){ >>>> return ts; >>>> } >>>> >>>> public void setTs(Timestamp ts){ >>>> this.ts = ts; >>>> } >>>> } >>>> ``` >>>> >>>> flink code: >>>> ``` >>>> StreamExecutionEnvironment bsEnv = >>>> StreamExecutionEnvironment.getExecutionEnvironment(); >>>> bsEnv.enableCheckpointing(10000); >>>> StreamTableEnvironment tEnv = StreamTableEnvironment.create(bsEnv); >>>> DataStream<UserInfo> dataStream = bsEnv.addSource(new MySource()) >>>> >>>> //构造hive catalog >>>> String name = "myhive"; >>>> String defaultDatabase = "default"; >>>> String hiveConfDir = "/Users/user/work/hive/conf"; // a local path >>>> String version = "3.1.2"; >>>> >>>> HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, >>>> version); >>>> tEnv.registerCatalog("myhive", hive); >>>> tEnv.useCatalog("myhive"); >>>> tEnv.getConfig().setSqlDialect(SqlDialect.HIVE); >>>> tEnv.useDatabase("db1"); >>>> >>>> tEnv.createTemporaryView("users", dataStream); >>>> >>>> String hiveSql = "CREATE external TABLE fs_table (\n" + >>>> " user_id STRING,\n" + >>>> " order_amount DOUBLE" + >>>> ") partitioned by (dt string,h string,m string) " + >>>> "stored as ORC " + >>>> "TBLPROPERTIES (\n" + >>>> " 'partition.time-extractor.timestamp-pattern'='$dt $h:$m:00',\n" + >>>> " 'sink.partition-commit.delay'='0s',\n" + >>>> " 'sink.partition-commit.trigger'='partition-time',\n" + >>>> " 'sink.partition-commit.policy.kind'='metastore'" + >>>> ")"; >>>> tEnv.executeSql(hiveSql); >>>> >>>> String insertSql = "SELECT * FROM users"; >>>> tEnv.executeSql(insertSql); >>>> ``` >>>> >>>> And this is my flink configuration: >>>> ``` >>>> jobmanager.memory.process.size: 1600m >>>> taskmanager.memory.process.size 4096m >>>> taskmanager.numberOfTaskSlots: 1 >>>> parallelism.default: 1 >>>> ``` >>>> >>>> And the exception is: java.util.concurrent.completionException: >>>> org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailable and >>>> request to ResourceManager for new slot failed. >>>> >>>> According the exception message, it means the resource is in sufficient, >>>> but the hadoop resource is enough, memory is 300+g, cores is 72, and the >>>> usage rate is lower about 30%. >>>> >>>> I have tried increase the taskmanager slot at flink run command with >>>> `flink run -ys`, but it is not effective. >>>> >>>> Here is the environment: >>>> flink version: 1.12.0 >>>> java: 1.8 >>>> >>>> Please check what’s the problem is, really appreciate it. Thanks. |
|
|
Hi Chenzuoli,
The NoSuchMethodError seems to indicate there's a dependency conflict. What's the hadoop version you're using? And could you also check whether there are multiple hadoop jars (in different versions) in the classpath? On Wed, Apr 14, 2021 at 5:10 PM chenzuoli <[hidden email]> wrote: > Hi: > This is the log attachment: > > https://www.icloud.com/attachment/?u=https%3A%2F%2Fcvws.icloud-content.com%2FB%2FAe5GSkj-YFuZTCZGaEu6GPihzx-7AdUBnM39Y4MbYWsiYk_NLx9zwJQQ%2F%24%7Bf%7D%3Fo%3DAlVY5QSsW5BX_oH9EoZOHG6QkCn05TIH8YH2miB0n_C5%26v%3D1%26x%3D3%26a%3DCAog36C0QwaK0BMfOhUFlqSplqI58eCIbiUgrnvfRrdbAn4SehDC8IDwjC8YwoD8w5YvIgEAKgkC6AMA_28vpaVSBKHPH7taBHPAlBBqJ2K-nETHh5awW3rtW5dSHzC3nDeIuqPUTZUvvcdtgOsNFwfHj7kUjHInHPbS8K9O0MrgZn-fA2aEEVj-bpqvfyInTOhEsY1j-6TEPySAjMS0%26e%3D1620955824%26fl%3D%26r%3D7464B4A1-AC88-496E-9608-6D9FEB86BFEA-1%26k%3D%24%7Buk%7D%26ckc%3Dcom.apple.largeattachment%26ckz%3DB0F3D90A-B949-4097-AD3F-ACE30FBE5D19%26p%3D30%26s%3Db1YldRmDMqM72hNP9DLBbOpRbOU&uk=Ir8SHK-FfM36NNDgmyiaYg&f=Images.zip&sz=42860073 > > > On Apr 14, 2021, at 17:06, chenzuoli <[hidden email]> wrote: > > > > Hi, > > > > Sorry for the pictures, I cannot get out the screenshots or text from > the company’s desktop, here is the new clear pictures > > > > > > > <PastedGraphic-8.png><PastedGraphic-9.png><PastedGraphic-10.png><PastedGraphic-11.png><PastedGraphic-12.png><PastedGraphic-13.png><PastedGraphic-14.png><PastedGraphic-15.png><PastedGraphic-16.png> > > > > > > > > > > > >> On Apr 14, 2021, at 16:17, Alessandro Solimando < > [hidden email] <mailto:[hidden email]>> > wrote: > >> > >> Hi Chenzuoli, > >> it seems that you are using Windows 10, you could follow this page to > >> improve the screenshots quality: > >> > https://support.microsoft.com/en-us/windows/open-snipping-tool-and-take-a-screenshot-a35ac9ff-4a58-24c9-3253-f12bac9f9d44#:~:text=To%20open%20the%20Snipping%20Tool,Snip%2C%20and%20then%20press%20Enter > < > https://support.microsoft.com/en-us/windows/open-snipping-tool-and-take-a-screenshot-a35ac9ff-4a58-24c9-3253-f12bac9f9d44#:~:text=To%20open%20the%20Snipping%20Tool,Snip%2C%20and%20then%20press%20Enter > >. > >> > >> Best regards, > >> Alessandro > >> > >> On Wed, 14 Apr 2021 at 10:11, Till Rohrmann <[hidden email] > <mailto:[hidden email]>> wrote: > >> > >>> Hi Chenzuoli, > >>> > >>> The pictures are unfortunately not readable for me. > >>> > >>> Cheers, > >>> Till > >>> > >>> On Wed, Apr 14, 2021 at 3:31 AM chenzuoli <[hidden email] > <mailto:[hidden email]>> wrote: > >>> > >>>> Download full resolution images > >>>> Available until May 14, 2021 > >>>> > >>>> < > https://www.icloud.com/attachment/?u=https%3A%2F%2Fcvws.icloud-content.com%2FB%2FAe5GSkj-YFuZTCZGaEu6GPihzx-7AdUBnM39Y4MbYWsiYk_NLx9zwJQQ%2F%24%7Bf%7D%3Fo%3DAlVY5QSsW5BX_oH9EoZOHG6QkCn05TIH8YH2miB0n_C5%26v%3D1%26x%3D3%26a%3DCAog36C0QwaK0BMfOhUFlqSplqI58eCIbiUgrnvfRrdbAn4SehDC8IDwjC8YwoD8w5YvIgEAKgkC6AMA_28vpaVSBKHPH7taBHPAlBBqJ2K-nETHh5awW3rtW5dSHzC3nDeIuqPUTZUvvcdtgOsNFwfHj7kUjHInHPbS8K9O0MrgZn-fA2aEEVj-bpqvfyInTOhEsY1j-6TEPySAjMS0%26e%3D1620955824%26fl%3D%26r%3D7464B4A1-AC88-496E-9608-6D9FEB86BFEA-1%26k%3D%24%7Buk%7D%26ckc%3Dcom.apple.largeattachment%26ckz%3DB0F3D90A-B949-4097-AD3F-ACE30FBE5D19%26p%3D30%26s%3Db1YldRmDMqM72hNP9DLBbOpRbOU&uk=Ir8SHK-FfM36NNDgmyiaYg&f=Images.zip&sz=42860073 > < > https://www.icloud.com/attachment/?u=https%3A%2F%2Fcvws.icloud-content.com%2FB%2FAe5GSkj-YFuZTCZGaEu6GPihzx-7AdUBnM39Y4MbYWsiYk_NLx9zwJQQ%2F%24%7Bf%7D%3Fo%3DAlVY5QSsW5BX_oH9EoZOHG6QkCn05TIH8YH2miB0n_C5%26v%3D1%26x%3D3%26a%3DCAog36C0QwaK0BMfOhUFlqSplqI58eCIbiUgrnvfRrdbAn4SehDC8IDwjC8YwoD8w5YvIgEAKgkC6AMA_28vpaVSBKHPH7taBHPAlBBqJ2K-nETHh5awW3rtW5dSHzC3nDeIuqPUTZUvvcdtgOsNFwfHj7kUjHInHPbS8K9O0MrgZn-fA2aEEVj-bpqvfyInTOhEsY1j-6TEPySAjMS0%26e%3D1620955824%26fl%3D%26r%3D7464B4A1-AC88-496E-9608-6D9FEB86BFEA-1%26k%3D%24%7Buk%7D%26ckc%3Dcom.apple.largeattachment%26ckz%3DB0F3D90A-B949-4097-AD3F-ACE30FBE5D19%26p%3D30%26s%3Db1YldRmDMqM72hNP9DLBbOpRbOU&uk=Ir8SHK-FfM36NNDgmyiaYg&f=Images.zip&sz=42860073 > >>Hi, > >>>> sorry for the debug log, I can take the photos instead of the log text > >>>> because of company policy, so if there is any log not clear, please > tell > >>>> me. Thanks. > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> On Apr 12, 2021, at 16:06, Till Rohrmann <[hidden email] > <mailto:[hidden email]>> wrote: > >>>> > >>>> Hi Chenzuoli, > >>>> > >>>> the exception says that Flink could not allocate enough slots. Could > you > >>>> share the DEBUG logs of the run with us. They should contain the > reason > >>>> why > >>>> the allocation of further resources failed. > >>>> > >>>> Cheers, > >>>> Till > >>>> > >>>> On Sun, Apr 11, 2021 at 5:59 AM chenzuoli <[hidden email] > <mailto:[hidden email]>> wrote: > >>>> > >>>> > >>>> > >>>> > https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html > < > https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html > > > >>>> < > >>>> > >>>> > https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html > < > https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/filesystem.html > > > >>>> > >>>> > >>>> Here is my code: > >>>> my datastream source: > >>>> ``` > >>>> public static class MySource implements SourceFunction<UserInfo>{ > >>>> > >>>> String userids[] = { > >>>> "4760858d-2bec-483c-a535-291de04b2247", > >>>> "67088699-d4f4-43f2-913c-481bff8a2dc5", > >>>> "72f7b6a8-e1a9-49b4-9a0b-770c41e01bfb", > >>>> "dfa27cb6-bd94-4bc0-a90b-f7beeb9faa8b", > >>>> "aabbaa50-72f4-495c-b3a1-70383ee9d6a4", > >>>> "3218bbb9-5874-4d37-a82d-3e35e52d1702", > >>>> "3ebfb9602ac07779||3ebfe9612a007979", > >>>> "aec20d52-c2eb-4436-b121-c29ad4097f6c", > >>>> "e7e896cd939685d7||e7e8e6c1930689d7", > >>>> "a4b1e1db-55ef-4d9d-b9d2-18393c5f59ee" > >>>> }; > >>>> > >>>> @Override > >>>> public void run(SourceContext<UserInfo> sourceContext) throws > >>>> Exception{ > >>>> > >>>> while (true){ > >>>> String userid = userids[(int) (Math.random() * > (userids.length > >>>> - 1))]; > >>>> UserInfo userInfo = new UserInfo(); > >>>> userInfo.setUserId(userid); > >>>> userInfo.setAmount(Math.random() * 100); > >>>> userInfo.setTs(new Timestamp(System.currentTimeMillis())); > >>>> sourceContext.collect(userInfo); > >>>> Thread.sleep(100); > >>>> } > >>>> } > >>>> > >>>> @Override > >>>> public void cancel(){ > >>>> > >>>> } > >>>> } > >>>> > >>>> public static class UserInfo implements java.io.Serializable{ > >>>> private String userId; > >>>> private Double amount; > >>>> private Timestamp ts; > >>>> > >>>> public String getUserId(){ > >>>> return userId; > >>>> } > >>>> > >>>> public void setUserId(String userId){ > >>>> this.userId = userId; > >>>> } > >>>> > >>>> public Double getAmount(){ > >>>> return amount; > >>>> } > >>>> > >>>> public void setAmount(Double amount){ > >>>> this.amount = amount; > >>>> } > >>>> > >>>> public Timestamp getTs(){ > >>>> return ts; > >>>> } > >>>> > >>>> public void setTs(Timestamp ts){ > >>>> this.ts = ts; > >>>> } > >>>> } > >>>> ``` > >>>> > >>>> flink code: > >>>> ``` > >>>> StreamExecutionEnvironment bsEnv = > >>>> StreamExecutionEnvironment.getExecutionEnvironment(); > >>>> bsEnv.enableCheckpointing(10000); > >>>> StreamTableEnvironment tEnv = StreamTableEnvironment.create(bsEnv); > >>>> DataStream<UserInfo> dataStream = bsEnv.addSource(new MySource()) > >>>> > >>>> //构造hive catalog > >>>> String name = "myhive"; > >>>> String defaultDatabase = "default"; > >>>> String hiveConfDir = "/Users/user/work/hive/conf"; // a local path > >>>> String version = "3.1.2"; > >>>> > >>>> HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, > >>>> version); > >>>> tEnv.registerCatalog("myhive", hive); > >>>> tEnv.useCatalog("myhive"); > >>>> tEnv.getConfig().setSqlDialect(SqlDialect.HIVE); > >>>> tEnv.useDatabase("db1"); > >>>> > >>>> tEnv.createTemporaryView("users", dataStream); > >>>> > >>>> String hiveSql = "CREATE external TABLE fs_table (\n" + > >>>> " user_id STRING,\n" + > >>>> " order_amount DOUBLE" + > >>>> ") partitioned by (dt string,h string,m string) " + > >>>> "stored as ORC " + > >>>> "TBLPROPERTIES (\n" + > >>>> " 'partition.time-extractor.timestamp-pattern'='$dt $h:$m:00',\n" + > >>>> " 'sink.partition-commit.delay'='0s',\n" + > >>>> " 'sink.partition-commit.trigger'='partition-time',\n" + > >>>> " 'sink.partition-commit.policy.kind'='metastore'" + > >>>> ")"; > >>>> tEnv.executeSql(hiveSql); > >>>> > >>>> String insertSql = "SELECT * FROM users"; > >>>> tEnv.executeSql(insertSql); > >>>> ``` > >>>> > >>>> And this is my flink configuration: > >>>> ``` > >>>> jobmanager.memory.process.size: 1600m > >>>> taskmanager.memory.process.size 4096m > >>>> taskmanager.numberOfTaskSlots: 1 > >>>> parallelism.default: 1 > >>>> ``` > >>>> > >>>> And the exception is: java.util.concurrent.completionException: > >>>> org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailable and > >>>> request to ResourceManager for new slot failed. > >>>> > >>>> According the exception message, it means the resource is in > sufficient, > >>>> but the hadoop resource is enough, memory is 300+g, cores is 72, and > the > >>>> usage rate is lower about 30%. > >>>> > >>>> I have tried increase the taskmanager slot at flink run command with > >>>> `flink run -ys`, but it is not effective. > >>>> > >>>> Here is the environment: > >>>> flink version: 1.12.0 > >>>> java: 1.8 > >>>> > >>>> Please check what’s the problem is, really appreciate it. Thanks. > > -- Best regards! Rui Li |
«
Return to (DEPRECATED) Apache Flink Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |