Side effect of DataStreamRel#translateToPlan


|
Hi all,
I noticed that the DataStreamRel#translateToPlan is non-idempotent, and that may cause the execution plan not as what we expected. Every time we call DataStreamRel#translateToPlan (in TableEnvirnment#explain, TableEnvirnment#writeToSink, etc), we add same operators in execution environment repeatedly. Should we eliminate the side effect of DataStreamRel#translateToPlan ? Best, Wangsan appendix tenv.registerTableSource("test_source", sourceTable) val t = tenv.sqlQuery("SELECT * from test_source") println(tenv.explain(t)) println(tenv.explain(t)) implicit val typeInfo = TypeInformation.of(classOf[Row]) tenv.toAppendStream(t) println(tenv.explain(t)) We call explain three times, and the Physical Execution Plan are all diffrent. == Abstract Syntax Tree == LogicalProject(f1=[$0], f2=[$1]) LogicalTableScan(table=[[test_source]]) == Optimized Logical Plan == StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) == Physical Execution Plan == Stage 1 : Data Source content : collect elements with CollectionInputFormat Stage 2 : Operator content : CsvTableSource(read fields: f1, f2) ship_strategy : FORWARD Stage 3 : Operator content : Map ship_strategy : FORWARD == Abstract Syntax Tree == LogicalProject(f1=[$0], f2=[$1]) LogicalTableScan(table=[[test_source]]) == Optimized Logical Plan == StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) == Physical Execution Plan == Stage 1 : Data Source content : collect elements with CollectionInputFormat Stage 2 : Operator content : CsvTableSource(read fields: f1, f2) ship_strategy : FORWARD Stage 3 : Operator content : Map ship_strategy : FORWARD Stage 4 : Data Source content : collect elements with CollectionInputFormat Stage 5 : Operator content : CsvTableSource(read fields: f1, f2) ship_strategy : FORWARD Stage 6 : Operator content : Map ship_strategy : FORWARD == Abstract Syntax Tree == LogicalProject(f1=[$0], f2=[$1]) LogicalTableScan(table=[[test_source]]) == Optimized Logical Plan == StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) == Physical Execution Plan == Stage 1 : Data Source content : collect elements with CollectionInputFormat Stage 2 : Operator content : CsvTableSource(read fields: f1, f2) ship_strategy : FORWARD Stage 3 : Operator content : Map ship_strategy : FORWARD Stage 4 : Data Source content : collect elements with CollectionInputFormat Stage 5 : Operator content : CsvTableSource(read fields: f1, f2) ship_strategy : FORWARD Stage 6 : Operator content : Map ship_strategy : FORWARD Stage 7 : Data Source content : collect elements with CollectionInputFormat Stage 8 : Operator content : CsvTableSource(read fields: f1, f2) ship_strategy : FORWARD Stage 9 : Operator content : Map ship_strategy : FORWARD Stage 10 : Operator content : to: Row ship_strategy : FORWARD Stage 11 : Data Source content : collect elements with CollectionInputFormat Stage 12 : Operator content : CsvTableSource(read fields: f1, f2) ship_strategy : FORWARD Stage 13 : Operator content : Map ship_strategy : FORWARD |
Re: Side effect of DataStreamRel#translateToPlan
|
|
Hi,
this sounds like a bug to me. Maybe the explain() method is not implemented correctly. Can you open an issue for it in Jira? Thanks, Timo Am 21.08.18 um 15:04 schrieb wangsan: > Hi all, > > I noticed that the DataStreamRel#translateToPlan is non-idempotent, and that may cause the execution plan not as what we expected. Every time we call DataStreamRel#translateToPlan (in TableEnvirnment#explain, TableEnvirnment#writeToSink, etc), we add same operators in execution environment repeatedly. > > Should we eliminate the side effect of DataStreamRel#translateToPlan ? > > Best, Wangsan > > appendix > > tenv.registerTableSource("test_source", sourceTable) > > val t = tenv.sqlQuery("SELECT * from test_source") > println(tenv.explain(t)) > println(tenv.explain(t)) > > implicit val typeInfo = TypeInformation.of(classOf[Row]) > tenv.toAppendStream(t) > println(tenv.explain(t)) > We call explain three times, and the Physical Execution Plan are all diffrent. > > == Abstract Syntax Tree == > LogicalProject(f1=[$0], f2=[$1]) > LogicalTableScan(table=[[test_source]]) > > == Optimized Logical Plan == > StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) > > == Physical Execution Plan == > Stage 1 : Data Source > content : collect elements with CollectionInputFormat > > Stage 2 : Operator > content : CsvTableSource(read fields: f1, f2) > ship_strategy : FORWARD > > Stage 3 : Operator > content : Map > ship_strategy : FORWARD > > > == Abstract Syntax Tree == > LogicalProject(f1=[$0], f2=[$1]) > LogicalTableScan(table=[[test_source]]) > > == Optimized Logical Plan == > StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) > > == Physical Execution Plan == > Stage 1 : Data Source > content : collect elements with CollectionInputFormat > > Stage 2 : Operator > content : CsvTableSource(read fields: f1, f2) > ship_strategy : FORWARD > > Stage 3 : Operator > content : Map > ship_strategy : FORWARD > > Stage 4 : Data Source > content : collect elements with CollectionInputFormat > > Stage 5 : Operator > content : CsvTableSource(read fields: f1, f2) > ship_strategy : FORWARD > > Stage 6 : Operator > content : Map > ship_strategy : FORWARD > > > == Abstract Syntax Tree == > LogicalProject(f1=[$0], f2=[$1]) > LogicalTableScan(table=[[test_source]]) > > == Optimized Logical Plan == > StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) > > == Physical Execution Plan == > Stage 1 : Data Source > content : collect elements with CollectionInputFormat > > Stage 2 : Operator > content : CsvTableSource(read fields: f1, f2) > ship_strategy : FORWARD > > Stage 3 : Operator > content : Map > ship_strategy : FORWARD > > Stage 4 : Data Source > content : collect elements with CollectionInputFormat > > Stage 5 : Operator > content : CsvTableSource(read fields: f1, f2) > ship_strategy : FORWARD > > Stage 6 : Operator > content : Map > ship_strategy : FORWARD > > Stage 7 : Data Source > content : collect elements with CollectionInputFormat > > Stage 8 : Operator > content : CsvTableSource(read fields: f1, f2) > ship_strategy : FORWARD > > Stage 9 : Operator > content : Map > ship_strategy : FORWARD > > Stage 10 : Operator > content : to: Row > ship_strategy : FORWARD > > Stage 11 : Data Source > content : collect elements with CollectionInputFormat > > Stage 12 : Operator > content : CsvTableSource(read fields: f1, f2) > ship_strategy : FORWARD > > Stage 13 : Operator > content : Map > ship_strategy : FORWARD > > |
|
|
Hi Timo,
I think this may not only affect explain() method. Method DataStreamRel#translateToPlan is called when we need translate a FlinkRelNode into DataStream or DataSet, we add desired operators in execution environment. By side effect, I mean that if we call DataStreamRel#translateToPlan on same RelNode several times, the same operators are added in execution environment more than once, but actually we need that for only one time. Correct me if I misunderstood that. I will open an issue late this day, if this is indeed a problem. Best, wangsan > On Aug 21, 2018, at 10:16 PM, Timo Walther <[hidden email]> wrote: > > Hi, > > this sounds like a bug to me. Maybe the explain() method is not implemented correctly. Can you open an issue for it in Jira? > > Thanks, > Timo > > > Am 21.08.18 um 15:04 schrieb wangsan: >> Hi all, >> >> I noticed that the DataStreamRel#translateToPlan is non-idempotent, and that may cause the execution plan not as what we expected. Every time we call DataStreamRel#translateToPlan (in TableEnvirnment#explain, TableEnvirnment#writeToSink, etc), we add same operators in execution environment repeatedly. >> >> Should we eliminate the side effect of DataStreamRel#translateToPlan ? >> >> Best, Wangsan >> >> appendix >> >> tenv.registerTableSource("test_source", sourceTable) >> >> val t = tenv.sqlQuery("SELECT * from test_source") >> println(tenv.explain(t)) >> println(tenv.explain(t)) >> >> implicit val typeInfo = TypeInformation.of(classOf[Row]) >> tenv.toAppendStream(t) >> println(tenv.explain(t)) >> We call explain three times, and the Physical Execution Plan are all diffrent. >> >> == Abstract Syntax Tree == >> LogicalProject(f1=[$0], f2=[$1]) >> LogicalTableScan(table=[[test_source]]) >> >> == Optimized Logical Plan == >> StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) >> >> == Physical Execution Plan == >> Stage 1 : Data Source >> content : collect elements with CollectionInputFormat >> >> Stage 2 : Operator >> content : CsvTableSource(read fields: f1, f2) >> ship_strategy : FORWARD >> >> Stage 3 : Operator >> content : Map >> ship_strategy : FORWARD >> >> >> == Abstract Syntax Tree == >> LogicalProject(f1=[$0], f2=[$1]) >> LogicalTableScan(table=[[test_source]]) >> >> == Optimized Logical Plan == >> StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) >> >> == Physical Execution Plan == >> Stage 1 : Data Source >> content : collect elements with CollectionInputFormat >> >> Stage 2 : Operator >> content : CsvTableSource(read fields: f1, f2) >> ship_strategy : FORWARD >> >> Stage 3 : Operator >> content : Map >> ship_strategy : FORWARD >> >> Stage 4 : Data Source >> content : collect elements with CollectionInputFormat >> >> Stage 5 : Operator >> content : CsvTableSource(read fields: f1, f2) >> ship_strategy : FORWARD >> >> Stage 6 : Operator >> content : Map >> ship_strategy : FORWARD >> >> >> == Abstract Syntax Tree == >> LogicalProject(f1=[$0], f2=[$1]) >> LogicalTableScan(table=[[test_source]]) >> >> == Optimized Logical Plan == >> StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) >> >> == Physical Execution Plan == >> Stage 1 : Data Source >> content : collect elements with CollectionInputFormat >> >> Stage 2 : Operator >> content : CsvTableSource(read fields: f1, f2) >> ship_strategy : FORWARD >> >> Stage 3 : Operator >> content : Map >> ship_strategy : FORWARD >> >> Stage 4 : Data Source >> content : collect elements with CollectionInputFormat >> >> Stage 5 : Operator >> content : CsvTableSource(read fields: f1, f2) >> ship_strategy : FORWARD >> >> Stage 6 : Operator >> content : Map >> ship_strategy : FORWARD >> >> Stage 7 : Data Source >> content : collect elements with CollectionInputFormat >> >> Stage 8 : Operator >> content : CsvTableSource(read fields: f1, f2) >> ship_strategy : FORWARD >> >> Stage 9 : Operator >> content : Map >> ship_strategy : FORWARD >> >> Stage 10 : Operator >> content : to: Row >> ship_strategy : FORWARD >> >> Stage 11 : Data Source >> content : collect elements with CollectionInputFormat >> >> Stage 12 : Operator >> content : CsvTableSource(read fields: f1, f2) >> ship_strategy : FORWARD >> >> Stage 13 : Operator >> content : Map >> ship_strategy : FORWARD >> >> |
Re: Side effect of DataStreamRel#translateToPlan
|
|
Hi Wangsan,
the bahavior of DataStreamRel#translateToPlan is more or less intended. That's why you call `toAppendStream` on the table environment. Because you add your pipeline to the environment (from source to current operator). However, the explain() method should not cause those side-effects. Regards, Timo Am 21.08.18 um 17:29 schrieb wangsan: > Hi Timo, > > I think this may not only affect explain() method. Method DataStreamRel#translateToPlan is called when we need translate a FlinkRelNode into DataStream or DataSet, we add desired operators in execution environment. By side effect, I mean that if we call DataStreamRel#translateToPlan on same RelNode several times, the same operators are added in execution environment more than once, but actually we need that for only one time. Correct me if I misunderstood that. > > I will open an issue late this day, if this is indeed a problem. > > Best, > wangsan > > > >> On Aug 21, 2018, at 10:16 PM, Timo Walther <[hidden email]> wrote: >> >> Hi, >> >> this sounds like a bug to me. Maybe the explain() method is not implemented correctly. Can you open an issue for it in Jira? >> >> Thanks, >> Timo >> >> >> Am 21.08.18 um 15:04 schrieb wangsan: >>> Hi all, >>> >>> I noticed that the DataStreamRel#translateToPlan is non-idempotent, and that may cause the execution plan not as what we expected. Every time we call DataStreamRel#translateToPlan (in TableEnvirnment#explain, TableEnvirnment#writeToSink, etc), we add same operators in execution environment repeatedly. >>> >>> Should we eliminate the side effect of DataStreamRel#translateToPlan ? >>> >>> Best, Wangsan >>> >>> appendix >>> >>> tenv.registerTableSource("test_source", sourceTable) >>> >>> val t = tenv.sqlQuery("SELECT * from test_source") >>> println(tenv.explain(t)) >>> println(tenv.explain(t)) >>> >>> implicit val typeInfo = TypeInformation.of(classOf[Row]) >>> tenv.toAppendStream(t) >>> println(tenv.explain(t)) >>> We call explain three times, and the Physical Execution Plan are all diffrent. >>> >>> == Abstract Syntax Tree == >>> LogicalProject(f1=[$0], f2=[$1]) >>> LogicalTableScan(table=[[test_source]]) >>> >>> == Optimized Logical Plan == >>> StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) >>> >>> == Physical Execution Plan == >>> Stage 1 : Data Source >>> content : collect elements with CollectionInputFormat >>> >>> Stage 2 : Operator >>> content : CsvTableSource(read fields: f1, f2) >>> ship_strategy : FORWARD >>> >>> Stage 3 : Operator >>> content : Map >>> ship_strategy : FORWARD >>> >>> >>> == Abstract Syntax Tree == >>> LogicalProject(f1=[$0], f2=[$1]) >>> LogicalTableScan(table=[[test_source]]) >>> >>> == Optimized Logical Plan == >>> StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) >>> >>> == Physical Execution Plan == >>> Stage 1 : Data Source >>> content : collect elements with CollectionInputFormat >>> >>> Stage 2 : Operator >>> content : CsvTableSource(read fields: f1, f2) >>> ship_strategy : FORWARD >>> >>> Stage 3 : Operator >>> content : Map >>> ship_strategy : FORWARD >>> >>> Stage 4 : Data Source >>> content : collect elements with CollectionInputFormat >>> >>> Stage 5 : Operator >>> content : CsvTableSource(read fields: f1, f2) >>> ship_strategy : FORWARD >>> >>> Stage 6 : Operator >>> content : Map >>> ship_strategy : FORWARD >>> >>> >>> == Abstract Syntax Tree == >>> LogicalProject(f1=[$0], f2=[$1]) >>> LogicalTableScan(table=[[test_source]]) >>> >>> == Optimized Logical Plan == >>> StreamTableSourceScan(table=[[test_source]], fields=[f1, f2], source=[CsvTableSource(read fields: f1, f2)]) >>> >>> == Physical Execution Plan == >>> Stage 1 : Data Source >>> content : collect elements with CollectionInputFormat >>> >>> Stage 2 : Operator >>> content : CsvTableSource(read fields: f1, f2) >>> ship_strategy : FORWARD >>> >>> Stage 3 : Operator >>> content : Map >>> ship_strategy : FORWARD >>> >>> Stage 4 : Data Source >>> content : collect elements with CollectionInputFormat >>> >>> Stage 5 : Operator >>> content : CsvTableSource(read fields: f1, f2) >>> ship_strategy : FORWARD >>> >>> Stage 6 : Operator >>> content : Map >>> ship_strategy : FORWARD >>> >>> Stage 7 : Data Source >>> content : collect elements with CollectionInputFormat >>> >>> Stage 8 : Operator >>> content : CsvTableSource(read fields: f1, f2) >>> ship_strategy : FORWARD >>> >>> Stage 9 : Operator >>> content : Map >>> ship_strategy : FORWARD >>> >>> Stage 10 : Operator >>> content : to: Row >>> ship_strategy : FORWARD >>> >>> Stage 11 : Data Source >>> content : collect elements with CollectionInputFormat >>> >>> Stage 12 : Operator >>> content : CsvTableSource(read fields: f1, f2) >>> ship_strategy : FORWARD >>> >>> Stage 13 : Operator >>> content : Map >>> ship_strategy : FORWARD >>> >>> > |
|
|
Hi Timo,
What confused me is why we need to rebuild the pipeline each time we try to convert the RelNode into datastream. In case I have this code (I want to write the query result into two target sinks) : val t = tenv.sqlQuery("SELECT * from test_source") t.insertInto("sink_1") t.insertInto("sink_2") And I got execution plan link this, 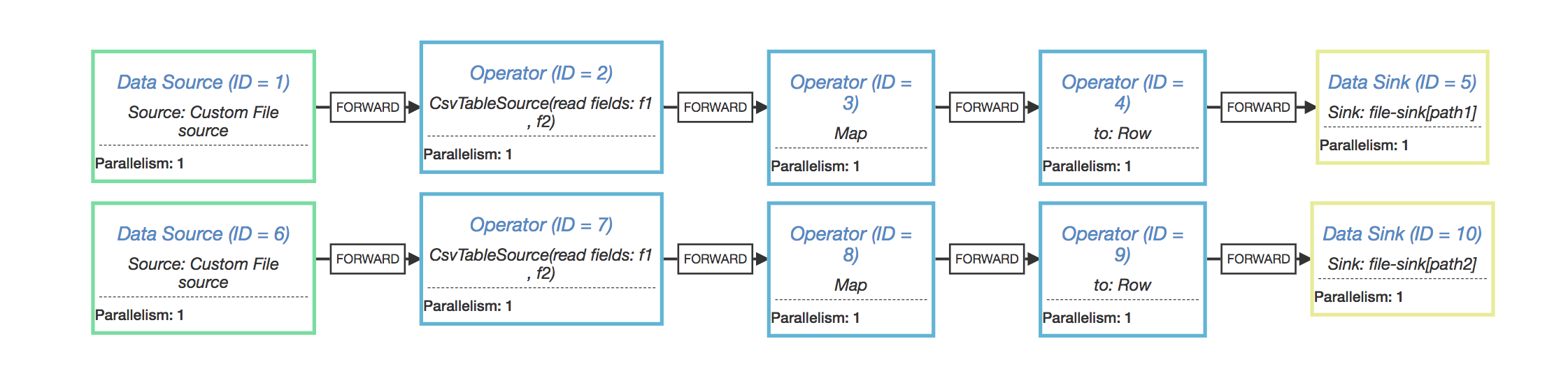 So we have two source operators, and they are just the same. But in some cases, when the backend connector does not support multiple consumers (eg, MQ that only deliver message once), one of the two target sink may not receive all the records (and that's the problem I meet :( ). I thought the behavior of the above code should be equivalent to this, val t = tenv.sqlQuery("SELECT * from test_source") val stream = tenv.toAppendStream[Row](t) stream.writeAsText("path_1") stream.writeAsText("path_2”) 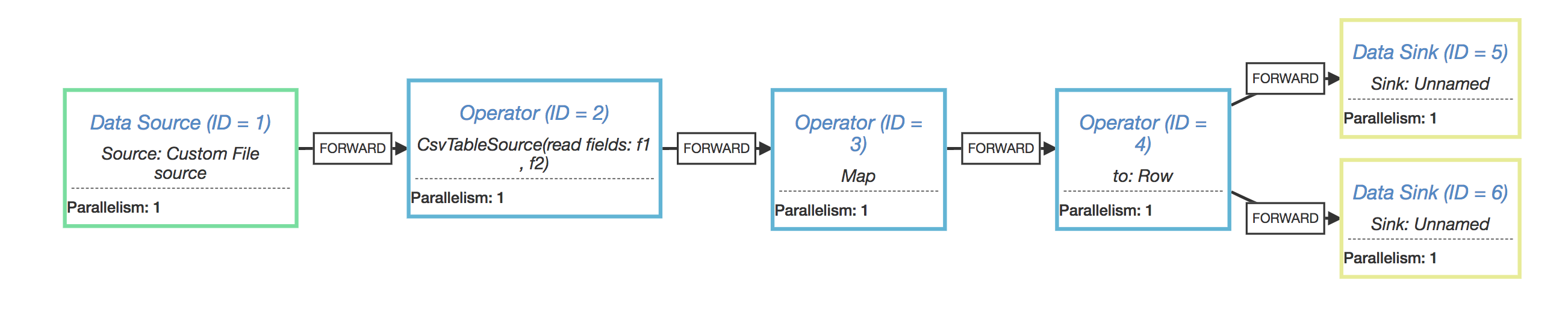 So, IMO, Instead of return a totally new one, why don’t we make the DataStreamRel#translateToPlan always return the same DataSteam as it is called the first time. What do you think? Best, wangsan
|
Re: Side effect of DataStreamRel#translateToPlan
|
|
Hi wangsan, > why don’t we make the DataStreamRel#translateToPlan always return the same DataSteam as it is called the first time. What do you think? You are definitely right. It would be nice if we support multi sink. The reason for this problem is that flink now use calcite to parse and optimize the sql while calcite don't support multi sink, so each time insertInto be called, the whole sql is treated as a new one. I think the community is already trying to solve the problem and probably be solved soon. Best, Hequn On Wed, Aug 22, 2018 at 4:15 PM wangsan <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |