Issues regarding Table-API


|
Hi there, I'm working on the Gradoop project at the University of Leipzig (https://github.com/dbs-leipzig/gradoop). Currently we're using the Batch-API - now we're investigating Table-API as an abstraction for Batch-API. I found 2 issues I want to discuss: 1. I get an error (Error while applying rule AggregateUnionAggregateRule) on compile time when having a DISTINCT on a result of a JOIN within an UNION, e.g. ( Java example: https://gist.github.com/lordon/27fc5277b0d5abd58158f4ec40cda384 2. As we have large workflows, several parts of such a workflow are reused at differents point within the workflow. For example: Two datasets get scanned, INTERSECTED and JOINED to another dataset. The resulting dataset is used as JOIN partner for six other datasets. Using Table-API the resulting operator tree looks like: 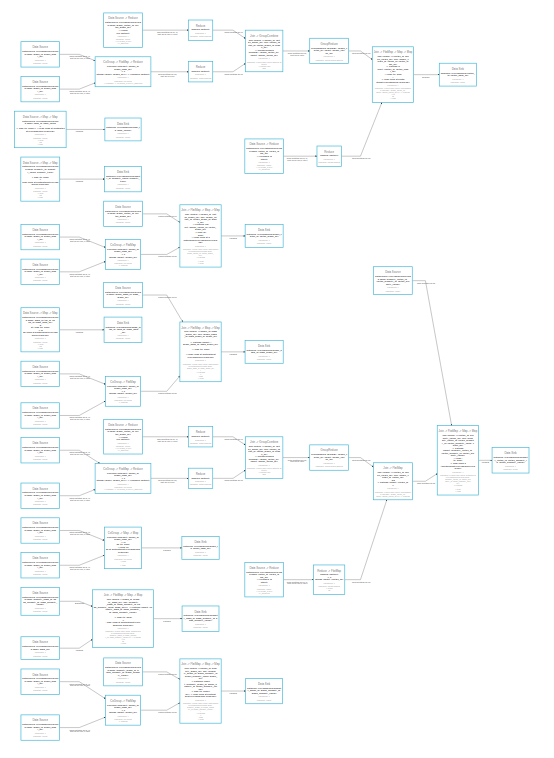 As you can see, the whole part of INTERSECTING and JOINING is executed for each reference. I guess this is because you decided to treat Flink Tables as VIEWs which get recalculated on each reference. In fact this doesn't make sense for our large workflows (note we're using the BatchEnvironment only). Is there any chance to avoid that behavior? Is there a possibility to allow Calcite to optimize/combine such common sub trees in the operator tree? Thanks in advance! Best, |
|
|
Hi Elias, For your question 2: this is doable, i think it will be resolved in future version of Flink. Best, Kurt On Tue, Jan 15, 2019 at 10:35 PM Elias Saalmann <[hidden email]> wrote:
|
Re: Issues regarding Table-API
|
|
Hi Elias,
Q1: Can you post the exception that you receive? Q2: This is already possible today by converting a Table into a DataSet and registering that DataSet again as a Table. Under the hood, the following is happening: As you said, Tables are views (or logical plans). Whenever, a Table is converted into a DataSet (or when it is emitted to a TableSink), the logical plan is optimized and translated into DataSet operators. By registering the DataSet again as a Table, the result of the DataSet can be queried. Every query will be attached to the previously computed DataSet operator, i.e., the operator is not replicated, but feeds its result into multiple queries (or multiple times into the same query). Best, Fabian Am Mi., 23. Jan. 2019 um 02:38 Uhr schrieb Kurt Young <[hidden email]>: > Hi Elias, > > For your question 2: this is doable, i think it will be resolved in future > version of Flink. > > Best, > Kurt > > > On Tue, Jan 15, 2019 at 10:35 PM Elias Saalmann < > [hidden email]> wrote: > >> Hi there, >> >> I'm working on the Gradoop project at the University of Leipzig ( >> https://github.com/dbs-leipzig/gradoop). Currently we're using the >> Batch-API - now we're investigating Table-API as an abstraction for >> Batch-API. I found 2 issues I want to discuss: >> >> 1. I get an error (Error while applying rule AggregateUnionAggregateRule) >> on compile time when having a DISTINCT on a result of a JOIN within an >> UNION, e.g. >> >> ( >> SELECT DISTINCT c >> FROM a JOIN b ON a = b >> ) >> UNION >> ( >> SELECT c >> FROM c >> ) >> >> Java example: >> https://gist.github.com/lordon/27fc5277b0d5abd58158f4ec40cda384 >> >> 2. As we have large workflows, several parts of such a workflow are >> reused at differents point within the workflow. For example: Two datasets >> get scanned, INTERSECTED and JOINED to another dataset. The resulting >> dataset is used as JOIN partner for six other datasets. Using Table-API the >> resulting operator tree looks like: >> [image: Workflow] >> >> As you can see, the whole part of INTERSECTING and JOINING is executed >> for each reference. I guess this is because you decided to treat Flink >> Tables as VIEWs which get recalculated on each reference. In fact this >> doesn't make sense for our large workflows (note we're using the >> BatchEnvironment only). Is there any chance to avoid that behavior? Is >> there a possibility to allow Calcite to optimize/combine such common sub >> trees in the operator tree? >> >> Thanks in advance! >> >> Best, >> Elias >> > |
| Free forum by Nabble | Edit this page |